



Онлайн
Alvaros
.
- Регистрация
- 14.05.16
- Сообщения
- 21.452
- Реакции
- 101
- Репутация
- 204
Обзор на лучших функций, включенных в последнюю итерацию Python.

Пришло время, выход новой версии Python неизбежен. Сейчас она в бета-версии (3.9.0b3), но скоро мы увидим полную версию Python 3.9.
Некоторые из новейших функций невероятно интересные, и будет восхитительно видеть их использование после релиза. Мы рассмотрим следующее:
Давайте сначала рассмотрим новые функции и то, как мы их будем использовать.
Объединение словарей
Одна из новых и уже моих любимых фич с синтаксисом. Если у нас есть два словаря a и b, которые нам нужно объединить, мы теперь используем операторы объединения.
У нас есть оператор слияния “|”:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
c = a | b
print(c)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
И оператор обновления “|=”, который обновляет исходный словарь:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
a |= b
print(a)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
Если наши словари имеют общий ключ, будет использована пара ключ-значение со второго словаря:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}
print(a | b)
[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}
Обновление словаря с помощью итераций
Еще одно интересное поведение оператора “|=” — возможность обновлять словарь новыми парами ключ-значение, используя итеративный объект — например, список или генератор:
a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))
a |= b
print(a)
[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
Если мы попробуем повторить то же самое со стандартным оператором объединения “|” мы получим TypeError, поскольку он будет разрешать только объединения между типами dict.
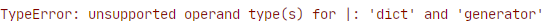
Тайп хинтинг
Python динамически типизирован, то есть нам не нужно указывать типы данных в нашем коде.
Это нормально, но иногда это может сбивать с толку, и внезапно гибкость Python становится более неприятной, чем что-либо еще.
Начиная с версии 3.5 мы могли указывать типы, но это было довольно громоздко. Текущее обновление действительно изменило подход, давайте посмотрим пример:
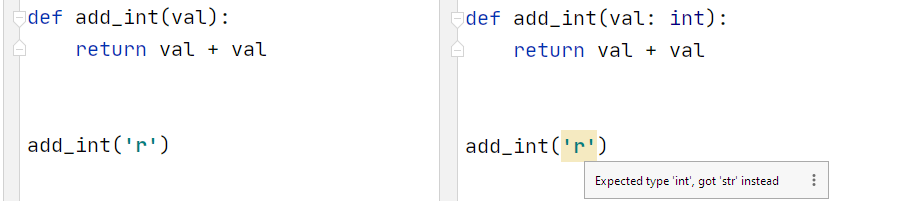
В нашей функции add_int мы явно хотим сложить два одинаковых числа(по какой-то загадочной неопределенной причине). Но наш редактор этого не знает, и совершенно нормально соединять две строки используя “+”, поэтому никакого предупреждения мы не увидим.
Теперь мы можем указать ожидаемый тип как int. Используя это, наш редактор сразу обнаруживает проблему.
Мы также можем получить сведения о ожидаемых типах, например:

Тайп хинтинг может использоваться везде — и благодаря новому синтаксису он теперь выглядит намного чище:

Строковые Методы
Не так эффектны, как другие новые функции, но все же стоит их упомянуть, поскольку это может быть полезно. Добавлены два новых строковых метода для удаления префиксов и суффиксов:
"Hello world".removeprefix("He")
[Out]: "llo world"
Hello world".removesuffix("ld")
[Out]: "Hello wor"
Новый парсер
Это скорее скрытое изменение, но оно может стать одним из наиболее значительных изменений для будущего развития Python.
В настоящее время Python использует грамматику, основанную преимущественно на LL(1), которая, в свою очередь, может быть проанализирована синтаксическим анализатором LL(1), который анализирует код сверху вниз, слева направо, с возможностью просмотра только одного токена.
Я почти не представляю, как это работает, но я могу рассказать вам про несколько актуальных проблем в Python из-за использования этого метода:
Все эти факторы (и многие другие, которые я просто не могу понять) оказывают одно большое влияние на Python; они ограничивают развитие языка.
Новый синтаксический анализатор, основанный на PEG, даст разработчикам Python значительно больше гибкости — и мы начнем это замечать начиная с Python 3.10.
Это то, что мы увидим в будущем Python 3.9. Если вы нетерпеливы, самая последняя бета-версия — 3.9.0b3 —

Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Читать еще
Пришло время, выход новой версии Python неизбежен. Сейчас она в бета-версии (3.9.0b3), но скоро мы увидим полную версию Python 3.9.
Некоторые из новейших функций невероятно интересные, и будет восхитительно видеть их использование после релиза. Мы рассмотрим следующее:
- Операторы объединения словарей
- Тайп хинтинг
- Два новых строковых метода
- Новый Python Parser — это очень круто
Давайте сначала рассмотрим новые функции и то, как мы их будем использовать.
Объединение словарей
Одна из новых и уже моих любимых фич с синтаксисом. Если у нас есть два словаря a и b, которые нам нужно объединить, мы теперь используем операторы объединения.
У нас есть оператор слияния “|”:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
c = a | b
print(c)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
И оператор обновления “|=”, который обновляет исходный словарь:
a = {1: 'a', 2: 'b', 3: 'c'}
b = {4: 'd', 5: 'e'}
a |= b
print(a)
[Out]: {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
Если наши словари имеют общий ключ, будет использована пара ключ-значение со второго словаря:
a = {1: 'a', 2: 'b', 3: 'c', 6: 'in both'}
b = {4: 'd', 5: 'e', 6: 'but different'}
print(a | b)
[Out]: {1: 'a', 2: 'b', 3: 'c', 6: 'but different', 4: 'd', 5: 'e'}
Обновление словаря с помощью итераций
Еще одно интересное поведение оператора “|=” — возможность обновлять словарь новыми парами ключ-значение, используя итеративный объект — например, список или генератор:
a = {'a': 'one', 'b': 'two'}
b = ((i, i**2) for i in range(3))
a |= b
print(a)
[Out]: {'a': 'one', 'b': 'two', 0: 0, 1: 1, 2: 4}
Если мы попробуем повторить то же самое со стандартным оператором объединения “|” мы получим TypeError, поскольку он будет разрешать только объединения между типами dict.
Тайп хинтинг
Python динамически типизирован, то есть нам не нужно указывать типы данных в нашем коде.
Это нормально, но иногда это может сбивать с толку, и внезапно гибкость Python становится более неприятной, чем что-либо еще.
Начиная с версии 3.5 мы могли указывать типы, но это было довольно громоздко. Текущее обновление действительно изменило подход, давайте посмотрим пример:
В нашей функции add_int мы явно хотим сложить два одинаковых числа(по какой-то загадочной неопределенной причине). Но наш редактор этого не знает, и совершенно нормально соединять две строки используя “+”, поэтому никакого предупреждения мы не увидим.
Теперь мы можем указать ожидаемый тип как int. Используя это, наш редактор сразу обнаруживает проблему.
Мы также можем получить сведения о ожидаемых типах, например:
Тайп хинтинг может использоваться везде — и благодаря новому синтаксису он теперь выглядит намного чище:
Строковые Методы
Не так эффектны, как другие новые функции, но все же стоит их упомянуть, поскольку это может быть полезно. Добавлены два новых строковых метода для удаления префиксов и суффиксов:
"Hello world".removeprefix("He")
[Out]: "llo world"
Hello world".removesuffix("ld")
[Out]: "Hello wor"
Новый парсер
Это скорее скрытое изменение, но оно может стать одним из наиболее значительных изменений для будущего развития Python.
В настоящее время Python использует грамматику, основанную преимущественно на LL(1), которая, в свою очередь, может быть проанализирована синтаксическим анализатором LL(1), который анализирует код сверху вниз, слева направо, с возможностью просмотра только одного токена.
Я почти не представляю, как это работает, но я могу рассказать вам про несколько актуальных проблем в Python из-за использования этого метода:
- Python содержит грамматику non-LL(1); из-за этого некоторые части текущей грамматики используют обходные пути, создавая ненужную сложность.
- LL(1) создает ограничения в синтаксисе Python (без возможных обходных путей).
You must be registered for see linksподчеркивает, что следующий код просто не может быть реализован с использованием текущего синтаксического анализатора (вызывает ошибку SyntaxError):
with (open("a_really_long_foo") as foo,
open("a_really_long_bar") as bar):
pass
- LL(1) разрывается с левой рекурсией в парсере (breaks with left-recursion in the parser). То есть конкретный рекурсивный синтаксис может вызвать бесконечный цикл в дереве синтаксического анализа, Гвидо ван Россум, создатель Python,
You must be registered for see links.
Все эти факторы (и многие другие, которые я просто не могу понять) оказывают одно большое влияние на Python; они ограничивают развитие языка.
Новый синтаксический анализатор, основанный на PEG, даст разработчикам Python значительно больше гибкости — и мы начнем это замечать начиная с Python 3.10.
Это то, что мы увидим в будущем Python 3.9. Если вы нетерпеливы, самая последняя бета-версия — 3.9.0b3 —
You must be registered for see links
.
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
Читать еще
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links