


Оффлайн
- Регистрация
- 21.07.20
- Сообщения
- 40.408
- Реакции
- 1
- Репутация
- 0
Привет, хабровчане. Как мы уже писали, в этом месяце OTUS запускает сразу два курса по машинному обучению, а именно
Цель этой статьи – рассказать о нашем первом опыте использования
Мы начнем обзор
Контекст
Мы в
MLflow
Основная цель MLflow – обеспечить дополнительный слой поверх машинного обучения, который позволил бы специалистам по data science работать практически с любой библиотекой машинного обучения (
MLflow обеспечивает три компонента:
Настройка MLflow
Для использования MLflow нужно сначала настроить всю среду Python, для этого мы воспользуемся
```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```
Установим требуемые библиотеки.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```
Запускаем Tracking UI
MLflow Tracking позволяет нам логировать и делать запросы к экспериментам с помощью Python и
# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3:///mlflow/artifacts/ \
--host localhost
--port 5000
MLflow рекомендует использовать постоянное файловое хранилище. Файловое хранилище – это место, где сервер будет хранить метаданные запусков и экспериментов. При запуске сервера убедитесь, что он указывает на постоянное файловое хранилище. Здесь для эксперимента мы просто воспользуемся /tmp.
Помните о том, что, если мы хотим использовать сервер mlflow для запуска старых экспериментов, они должны присутствовать в файловом хранилище. Однако и без этого мы бы смогли их использовать в UDF, поскольку нам нужен только путь до модели.
Tracking UI хранит артефакты в бакете S3
Запуск моделей
Как только будет работать Tracking-сервер, можно начинать обучать модели.
В качестве примера мы воспользуемся модификацией wine из примера MLflow в
MLFLOW_TRACKING_URI=
--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csv
Как мы уже говорили, MLflow позволяет логировать параметры, метрики и артефакты моделей, чтобы можно было отслеживать, как они развиваются по мере итераций. Эта функция крайне полезна, поскольку так мы сможем воспроизвести лучшую модель, обратившись в Tracking-серверу или поняв, какой код выполнил нужную итерацию, воспользовавшись логами git hash коммитов.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")
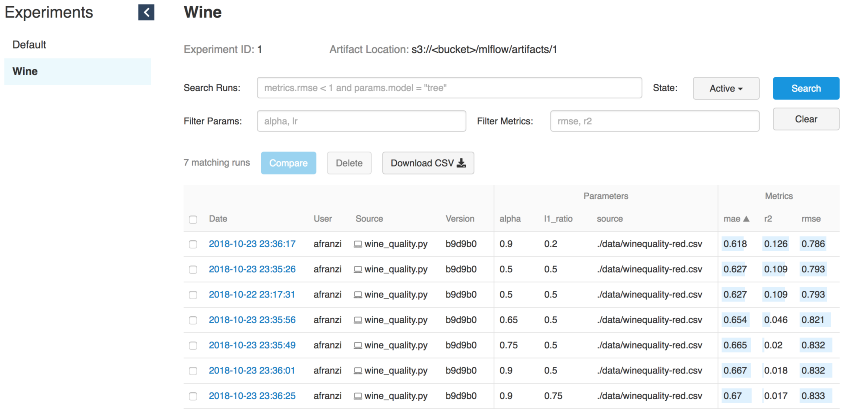
Итерации wine
Серверная часть для модели
Чтобы обеспечить модель сервером нам понадобится запущенный tracking-сервер (см. интерфейс запуска) и Run ID модели.

Run ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=
--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path model
Для обслуживания моделей с помощью функционала MLflow serve, нам понадобится доступ к Tracking UI, чтобы получать информацию о модели просто указав --run_id.
Как только модель связывается с Tracking-сервером, мы можем получить новую конечную точку модели.
# Query Tracking Server Endpoint
curl -X POST \
-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}
Запуск моделей из Spark
Несмотря на то, что Tracking-сервер достаточно мощный для облуживания моделей в режиме реального времени, их обучения и использования функционалаserve (источник:
Представьте, что вы просто провели обучение в оффлайне, а потом применили выходную модель ко всем вашим данным. Именно тут Spark и MLflow покажут себя с лучшей стороны.
Устанавливаем PySpark + Jupyter + Spark
Чтобы показать, как мы применяем модели MLflow к датафреймам Spark, нужно настроить совместную работу Jupyter notebooks с PySpark.
Начните с установки последней стабильной версии
cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀
Установите PySpark и Jupyter в виртуальную среду:
pip install pyspark jupyter
Настройте переменные среды:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"
Определив notebook-dir, мы сможем хранить наши notebook-и в желаемой папке.
Запускаем Jupyter из PySpark
Поскольку мы смогли настроить Jupiter в качестве драйвера PySpark, теперь мы можем запускать Jupyter notebook в контексте PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp]
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:

Как было сказано выше, MLflow предоставляет функцию логирования артефактов модели в S3. Как только у нас в руках появляется выбранная модель, мы имеем возможность импортировать ее как UDF с помощью модуля mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3:///mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)

PySpark – Вывод прогноза качества вина
До этого момента мы говорили о том, как использовать PySpark с MLflow, запуская прогнозирование качества вина на всем наборе данных wine. Но что делать, если нужно использовать модули Python MLflow из Scala Spark?
Мы протестировали и это, разделив контекст Spark между Scala и Python. То есть мы зарегистрировали MLflow UDF в Python, и использовали его из Scala (да, возожно, не лучшее решение, но что имеем).
Scala Spark + MLflow
Для этого примера мы добавим
Устанавливаем Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```
Как видно из прикрепленного notebook-а, UDF используется совместно Spark и PySpark. Мы надеемся, что эта часть будет полезна тем, кто любит Scala и хочет развернуть модели машинного обучения на продакшене.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_. ]+".r
]+".r
def getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.]+
getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.]+
In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Следующие шаги
Несмотря на то, что на момент написания статьи MLflow находится в Alpha-версии, она выглядит довольно многообещающе. Одна лишь возможность запускать несколько фреймворков машинного обучения и использовать их из одной конечной точки выводит рекомендательные системы на новый уровень.
К тому же, MLflow сближает Data-инженеров и специалистов по Data Science, прокладывая между ними общий слой.
После этого исследования MLflow, мы уверены, что пойдем дальше и будем использовать ее для наших пайплайнов Spark и в рекомендательных системах.
Было бы неплохо синхронизировать файловое хранилище с базой данных, вместо файловой системы. Так мы должны получить несколько конечных точек, которые могут использовать одно и то же файловое хранилище. Например, использовать несколько экземпляров
Подводя итоги, хочется сказать спасибо сообществу MLFlow за то, что делаете нашу работу с данными интереснее.
Если вы играетесь с MLflow, не стесняйтесь писать нам и рассказывать, как вы его используете, и тем более, если используете его на продакшене.
Узнать подробнее о курсах:
Читать ещё:
You must be registered for see links
и
You must be registered for see links
. В связи с этим продолжаем делиться полезным материалом.Цель этой статьи – рассказать о нашем первом опыте использования
You must be registered for see links
.Мы начнем обзор
You must be registered for see links
с его tracking-сервера и прологируем все итерации исследования. Затем поделимся опытом соединения Spark с MLflow с помощью UDF. Контекст
Мы в
You must be registered for see links
используем машинное обучение и искусственный интеллект, чтобы дать людям возможность заботиться о своем здоровье и благополучии. Поэтому модели машинного обучения лежат в основе разрабатываемых нами продуктов обработки данных, и именно поэтому наше внимание привлекла MLflow — платформа с открытым исходным кодом, которая охватывает все аспекты жизненного цикла машинного обучения. MLflow
Основная цель MLflow – обеспечить дополнительный слой поверх машинного обучения, который позволил бы специалистам по data science работать практически с любой библиотекой машинного обучения (
You must be registered for see links
,
You must be registered for see links
,
You must be registered for see links
,
You must be registered for see links
,
You must be registered for see links
и
You must be registered for see links
), выводя ее работу на новый уровень.MLflow обеспечивает три компонента:
- Tracking – запись и запросы к экспериментам: код, данные, конфигурация и результаты. Следить за процессом создания модели очень важно.
- Projects – Формат упаковки для запуска на любой платформе (например,
You must be registered for see links)
- Models – общий формат отправки моделей в различные инструменты развертывания.
MLflow (на момент написания статьи в alpha-версии) — платформа с открытым исходным кодом, которая позволяет управлять жизненным циклом машинного обучения, в том числе экспериментами, переиспользованием и развертыванием.
Настройка MLflow
Для использования MLflow нужно сначала настроить всю среду Python, для этого мы воспользуемся
You must be registered for see links
(чтобы установить Python на Mac, загляните
You must be registered for see links
). Так мы сможем создать виртуальную среду, куда установим все необходимые для запуска библиотеки.```
pyenv install 3.7.0
pyenv global 3.7.0 # Use Python 3.7
mkvirtualenv mlflow # Create a Virtual Env with Python 3.7
workon mlflow
```
Установим требуемые библиотеки.
```
pip install mlflow==0.7.0 \
Cython==0.29 \
numpy==1.14.5 \
pandas==0.23.4 \
pyarrow==0.11.0
```
Примечание: мы используем PyArrow для запуска таких моделей как UDF. Версии PyArrow и Numpy нужно было поправить, поскольку последние версии конфликтовали между собой.
Запускаем Tracking UI
MLflow Tracking позволяет нам логировать и делать запросы к экспериментам с помощью Python и
You must be registered for see links
API. Помимо этого, можно определить, где хранить артефакты модели (localhost,
You must be registered for see links
,
You must be registered for see links
,
You must be registered for see links
или
You must be registered for see links
). Поскольку в Alpha Health мы пользуемся AWS, в качестве хранилища артефактов будет S3.# Running a Tracking Server
mlflow server \
--file-store /tmp/mlflow/fileStore \
--default-artifact-root s3:///mlflow/artifacts/ \
--host localhost
--port 5000
MLflow рекомендует использовать постоянное файловое хранилище. Файловое хранилище – это место, где сервер будет хранить метаданные запусков и экспериментов. При запуске сервера убедитесь, что он указывает на постоянное файловое хранилище. Здесь для эксперимента мы просто воспользуемся /tmp.
Помните о том, что, если мы хотим использовать сервер mlflow для запуска старых экспериментов, они должны присутствовать в файловом хранилище. Однако и без этого мы бы смогли их использовать в UDF, поскольку нам нужен только путь до модели.
Примечание: Имейте в виду, что Tracking UI и клиент модели должны иметь доступ к местоположению артефакта. То есть вне зависимости от того, что Tracking UI располагается в экземпляре EC2, при локальном запуске MLflow у машины должен быть прямой доступ к S3 для записи моделей артефактов.
Tracking UI хранит артефакты в бакете S3
Запуск моделей
Как только будет работать Tracking-сервер, можно начинать обучать модели.
В качестве примера мы воспользуемся модификацией wine из примера MLflow в
You must be registered for see links
.MLFLOW_TRACKING_URI=
You must be registered for see links
python wine_quality.py \--alpha 0.9
--l1_ration 0.5
--wine_file ./data/winequality-red.csv
Как мы уже говорили, MLflow позволяет логировать параметры, метрики и артефакты моделей, чтобы можно было отслеживать, как они развиваются по мере итераций. Эта функция крайне полезна, поскольку так мы сможем воспроизвести лучшую модель, обратившись в Tracking-серверу или поняв, какой код выполнил нужную итерацию, воспользовавшись логами git hash коммитов.
with mlflow.start_run():
... model ...
mlflow.log_param("source", wine_path)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.set_tag('domain', 'wine')
mlflow.set_tag('predict', 'quality')
mlflow.sklearn.log_model(lr, "model")
Итерации wine
Серверная часть для модели
Tracking-сервер MLflow, запущенный с помощью команды “mlflow server”, имеет REST API для отслеживания запусков и записи данных в локальную файловую систему. Вы можете указать адрес tracking-сервера с помощью переменной среды «MLFLOW_TRACKING_URI» и tracking API MLflow автоматически свяжется с tracking-сервером по этому адресу, чтобы создать/получить информацию о запуске, метрики логов и т.д.
Источник:
Источник:
You must be registered for see links
Чтобы обеспечить модель сервером нам понадобится запущенный tracking-сервер (см. интерфейс запуска) и Run ID модели.
Run ID
# Serve a sklearn model through 127.0.0.0:5005
MLFLOW_TRACKING_URI=
You must be registered for see links
mlflow sklearn serve \--port 5005 \
--run_id 0f8691808e914d1087cf097a08730f17 \
--model-path model
Для обслуживания моделей с помощью функционала MLflow serve, нам понадобится доступ к Tracking UI, чтобы получать информацию о модели просто указав --run_id.
Как только модель связывается с Tracking-сервером, мы можем получить новую конечную точку модели.
# Query Tracking Server Endpoint
curl -X POST \
You must be registered for see links
\-H 'Content-Type: application/json' \
-d '[
{
"fixed acidity": 3.42,
"volatile acidity": 1.66,
"citric acid": 0.48,
"residual sugar": 4.2,
"chloridessssss": 0.229,
"free sulfur dsioxide": 19,
"total sulfur dioxide": 25,
"density": 1.98,
"pH": 5.33,
"sulphates": 4.39,
"alcohol": 10.8
}
]'
> {"predictions": [5.825055635303461]}
Запуск моделей из Spark
Несмотря на то, что Tracking-сервер достаточно мощный для облуживания моделей в режиме реального времени, их обучения и использования функционалаserve (источник:
You must be registered for see links
), применение Spark (batch или streaming) – еще более мощное решение за счет распределенности. Представьте, что вы просто провели обучение в оффлайне, а потом применили выходную модель ко всем вашим данным. Именно тут Spark и MLflow покажут себя с лучшей стороны.
Устанавливаем PySpark + Jupyter + Spark
Источник:
You must be registered for see links
Чтобы показать, как мы применяем модели MLflow к датафреймам Spark, нужно настроить совместную работу Jupyter notebooks с PySpark.
Начните с установки последней стабильной версии
You must be registered for see links
:cd ~/Downloads/
tar -xzf spark-2.4.3-bin-hadoop2.7.tgz
mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 ~/
ln -s ~/spark-2.4.3-bin-hadoop2.7 ~/spark̀
Установите PySpark и Jupyter в виртуальную среду:
pip install pyspark jupyter
Настройте переменные среды:
export SPARK_HOME=~/spark
export PATH=$SPARK_HOME/bin:$PATH
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --notebook-dir=${HOME}/Projects/notebooks"
Определив notebook-dir, мы сможем хранить наши notebook-и в желаемой папке.
Запускаем Jupyter из PySpark
Поскольку мы смогли настроить Jupiter в качестве драйвера PySpark, теперь мы можем запускать Jupyter notebook в контексте PySpark.
(mlflow) afranzi:~$ pyspark
[I 19:05:01.572 NotebookApp] sparkmagic extension enabled!
[I 19:05:01.573 NotebookApp] Serving notebooks from local directory: /Users/afranzi/Projects/notebooks
[I 19:05:01.573 NotebookApp] The Jupyter Notebook is running at:
[I 19:05:01.573 NotebookApp]
You must be registered for see links
[I 19:05:01.573 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 19:05:01.574 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
You must be registered for see links
Как было сказано выше, MLflow предоставляет функцию логирования артефактов модели в S3. Как только у нас в руках появляется выбранная модель, мы имеем возможность импортировать ее как UDF с помощью модуля mlflow.pyfunc.
import mlflow.pyfunc
model_path = 's3:///mlflow/artifacts/1/0f8691808e914d1087cf097a08730f17/artifacts/model'
wine_path = '/Users/afranzi/Projects/data/winequality-red.csv'
wine_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = spark.read.format("csv").option("header", "true").option('delimiter', ';').load(wine_path)
columns = [ "fixed acidity", "volatile acidity", "citric acid",
"residual sugar", "chlorides", "free sulfur dioxide",
"total sulfur dioxide", "density", "pH",
"sulphates", "alcohol"
]
df.withColumn('prediction', wine_udf(*columns)).show(100, False)
PySpark – Вывод прогноза качества вина
До этого момента мы говорили о том, как использовать PySpark с MLflow, запуская прогнозирование качества вина на всем наборе данных wine. Но что делать, если нужно использовать модули Python MLflow из Scala Spark?
Мы протестировали и это, разделив контекст Spark между Scala и Python. То есть мы зарегистрировали MLflow UDF в Python, и использовали его из Scala (да, возожно, не лучшее решение, но что имеем).
Scala Spark + MLflow
Для этого примера мы добавим
You must be registered for see links
в существующий Jupiter. Устанавливаем Spark + Toree + Jupyter
pip install toree
jupyter toree install --spark_home=${SPARK_HOME} --sys-prefix
jupyter kernelspec list
```
```
Available kernels:
apache_toree_scala /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/apache_toree_scala
python3 /Users/afranzi/.virtualenvs/mlflow/share/jupyter/kernels/python3
```
Как видно из прикрепленного notebook-а, UDF используется совместно Spark и PySpark. Мы надеемся, что эта часть будет полезна тем, кто любит Scala и хочет развернуть модели машинного обучения на продакшене.
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{Column, DataFrame}
import scala.util.matching.Regex
val FirstAtRe: Regex = "^_".r
val AliasRe: Regex = "[\\s_.
]+".rdef getFieldAlias(field_name: String): String = {
FirstAtRe.replaceAllIn(AliasRe.replaceAllIn(field_name, "_"), "")
}
def selectFieldsNormalized(columns: List[String])(df: DataFrame): DataFrame = {
val fieldsToSelect: List[Column] = columns.map(field =>
col(field).as(getFieldAlias(field))
)
df.select(fieldsToSelect: _*)
}
def normalizeSchema(df: DataFrame): DataFrame = {
val schema = df.columns.toList
df.transform(selectFieldsNormalized(schema))
}
FirstAtRe = ^_
AliasRe = [\s_.
]+getFieldAlias: (field_name: String)String
selectFieldsNormalized: (columns: List[String])(df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
normalizeSchema: (df: org.apache.spark.sql.DataFrame)org.apache.spark.sql.DataFrame
Out[1]:
[\s_.
]+In [2]:
val winePath = "~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv"
val modelPath = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
winePath = ~/Research/mlflow-workshop/examples/wine_quality/data/winequality-red.csv
modelPath = /tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
Out[2]:
/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model
In [3]:
val df = spark.read
.format("csv")
.option("header", "true")
.option("delimiter", ";")
.load(winePath)
.transform(normalizeSchema)
df = [fixed_acidity: string, volatile_acidity: string ... 10 more fields]
Out[3]:
[fixed_acidity: string, volatile_acidity: string ... 10 more fields]
In [4]:
%%PySpark
import mlflow
from mlflow import pyfunc
model_path = "/tmp/mlflow/artifactStore/0/96cba14c6e4b452e937eb5072467bf79/artifacts/model"
wine_quality_udf = mlflow.pyfunc.spark_udf(spark, model_path)
spark.udf.register("wineQuality", wine_quality_udf)
Out[4]:
.predict at 0x1116a98c8>
In [6]:
df.createOrReplaceTempView("wines")
In [10]:
%%SQL
SELECT
quality,
wineQuality(
fixed_acidity,
volatile_acidity,
citric_acid,
residual_sugar,
chlorides,
free_sulfur_dioxide,
total_sulfur_dioxide,
density,
pH,
sulphates,
alcohol
) AS prediction
FROM wines
LIMIT 10
Out[10]:
+-------+------------------+
|quality| prediction|
+-------+------------------+
| 5| 5.576883967129615|
| 5| 5.50664776916154|
| 5| 5.525504822954496|
| 6| 5.504311247097457|
| 5| 5.576883967129615|
| 5|5.5556903912725755|
| 5| 5.467882654744997|
| 7| 5.710602976324739|
| 7| 5.657319539336507|
| 5| 5.345098606538708|
+-------+------------------+
In [17]:
spark.catalog.listFunctions.filter('name like "%wineQuality%").show(20, false)
+-----------+--------+-----------+---------+-----------+
|name |database|description|className|isTemporary|
+-----------+--------+-----------+---------+-----------+
|wineQuality|null |null |null |true |
+-----------+--------+-----------+---------+-----------+
Следующие шаги
Несмотря на то, что на момент написания статьи MLflow находится в Alpha-версии, она выглядит довольно многообещающе. Одна лишь возможность запускать несколько фреймворков машинного обучения и использовать их из одной конечной точки выводит рекомендательные системы на новый уровень.
К тому же, MLflow сближает Data-инженеров и специалистов по Data Science, прокладывая между ними общий слой.
После этого исследования MLflow, мы уверены, что пойдем дальше и будем использовать ее для наших пайплайнов Spark и в рекомендательных системах.
Было бы неплохо синхронизировать файловое хранилище с базой данных, вместо файловой системы. Так мы должны получить несколько конечных точек, которые могут использовать одно и то же файловое хранилище. Например, использовать несколько экземпляров
You must be registered for see links
и
You must be registered for see links
с одним и тем же Glue metastore.Подводя итоги, хочется сказать спасибо сообществу MLFlow за то, что делаете нашу работу с данными интереснее.
Если вы играетесь с MLflow, не стесняйтесь писать нам и рассказывать, как вы его используете, и тем более, если используете его на продакшене.
Узнать подробнее о курсах:
You must be registered for see links
You must be registered for see links
Читать ещё:
-
You must be registered for see links
-
You must be registered for see links
-
You must be registered for see links