



Онлайн
Alvaros
.
- Регистрация
- 14.05.16
- Сообщения
- 21.452
- Реакции
- 101
- Репутация
- 204
В
С архитектурной точки зрения платформа IoT требует решить следующие задачи:
Одной из особенностей IoT платформы является независимость между объектами и сигналами, что позволяет выполнять параллельные вычисления, повышая производительность.
Данные, поступающие с датчиков, собираются из источников, таких как ПЛК, DCS, микроконтроллеров и т.п и могут храниться во временной области для избежание потери данных из-за проблем с подключением. Данные могут быть временным рядом, такими как событие, полуструктурированные данные, такие как логи и двоичные файлы, или неструктурированные, как изображение. Данные и события временного ряда собираются часто (от каждой секунды до нескольких минут). Затем они отправляются по сети и сохраняются в централизованном озере данных (data lake) и базе данных временных рядов (time-series database TSDB). Data lake может быть облачным, локальным центром обработки данных или сторонней системой хранения.
Данные могут быть немедленно обработаны с использованием анализа потока данных, который называется «hot path», с механизмом проверки правил, основанном на простой или интеллектуальной уставке. Продвинутая аналитика может включать: цифровые близнецы, машинное обучение, глубокое обучение или аналитика на основе физических характеристик. Такая система может обрабатывать большой объем данных (от десяти минут до месяца) с разных датчиков. Эти данные хранятся в промежуточном хранилище. Эта аналитика называется «cold path», и как правило, запускается планировщиком или доступностью данных и требует большого количества вычислительных ресурсов. Продвинутая аналитика часто нуждается в дополнительной информации, такой как модель контролируемой машины и эксплуатационные атрибуты; эта информация содержится в asset registry. Asset registry содержит информацию о типе актива, включая его имя, серийный номер, символическое имя, местоположение, рабочие возможности, историю комплектующих, из которых он состоит, и роль, которую он играет в производственном процессе. В asset registry мы можем хранить список измерений каждого актива, логическое имя, единицу измерения и диапазон границ. В промышленном секторе эта статическая информация важна для правильной аналитической модели.
Причины разработки кастомной платформы:
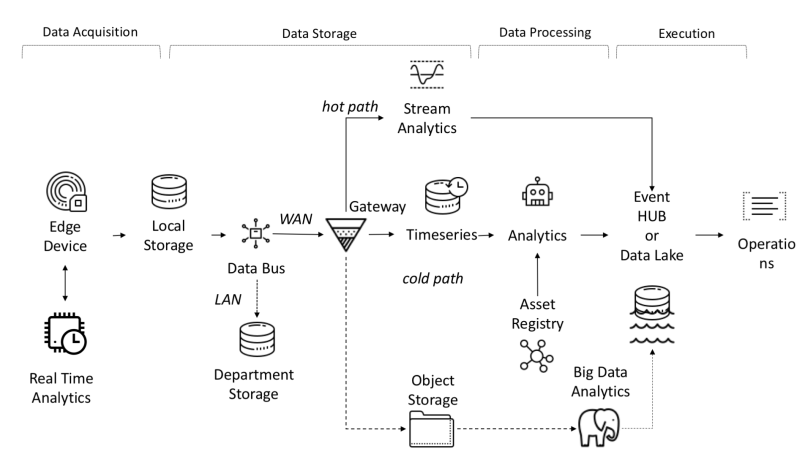
Cквозной поток данных в I-IoT
Пример кастомной реализации Edge-платформы
На данном рисунке показана реализация следующих звеньев платформы:
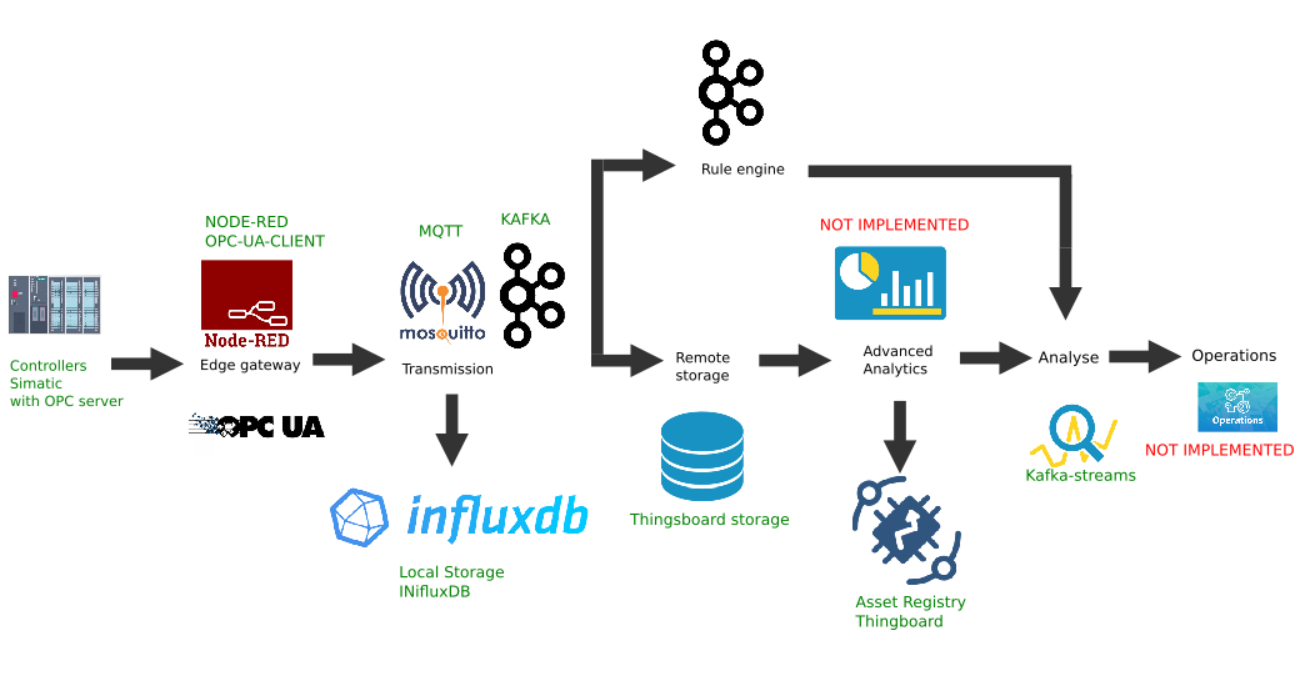
Node-red Edge gateway
В качестве шлюза граничных вычислений будем использовать Node-red, как простую настраиваемую платформу, имеющую множество различных плагинов. Роль промышленного адаптера (Industrial adapter) играет плагин node-red-contrib-opcua. Для множественного сбора данных с контроллера способом подписки используются ноды: OpcUa-Browser и OpcUa-client. В OPC браузер ноде настраивается url OPC-сервера (endpoint) и топик, в котором указано пространство имен и имя читаемого блока данных, например ns=3;s=«HMI_Alarms_Area». В OPC-клиент ноде также указывается url OPC-сервера, в качестве действия (Action) устанавливается SUBSCRIBE и интервал обновления данных.
Node-red main flow
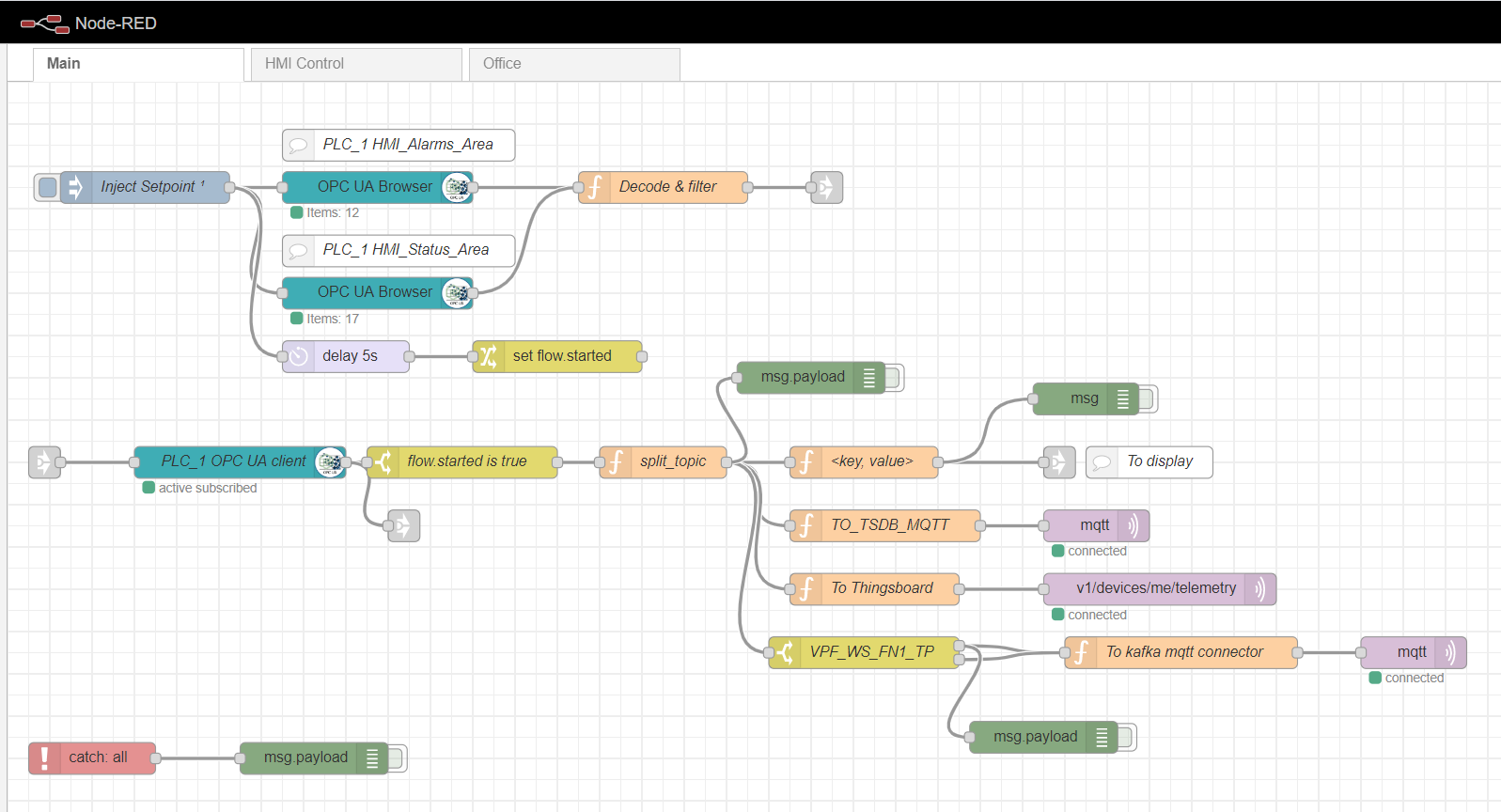
Настройка ноды OPC-browser

Настройка ноды OPC-client

Для того, чтобы выполнилась подписка на чтения множественных данных, необходимо подготовить и загрузить топики тегов чтения с контроллера, согласно OPC протокола. Для этого вначале используется inject нода с чекбоксом only once, которая тригерит единократное чтения блоков данных, указанных в нодах OPC-браузера. Затем данные обрабатываются функцией Decode&filter. После чего нода OPC-клиента подписывается и читает изменяющиеся данные с контроллера. Дальнейшая обработка потока зависит от конкретной реализации и требований. В своем примере я обрабатываю данные для дальнейшей отсылки их в MQTT брокер на разные топики.
Вкладки HMI control и Office представляют собой простую реализуцию HMI на базе Scadavis.io и node-red dashboard, как описано
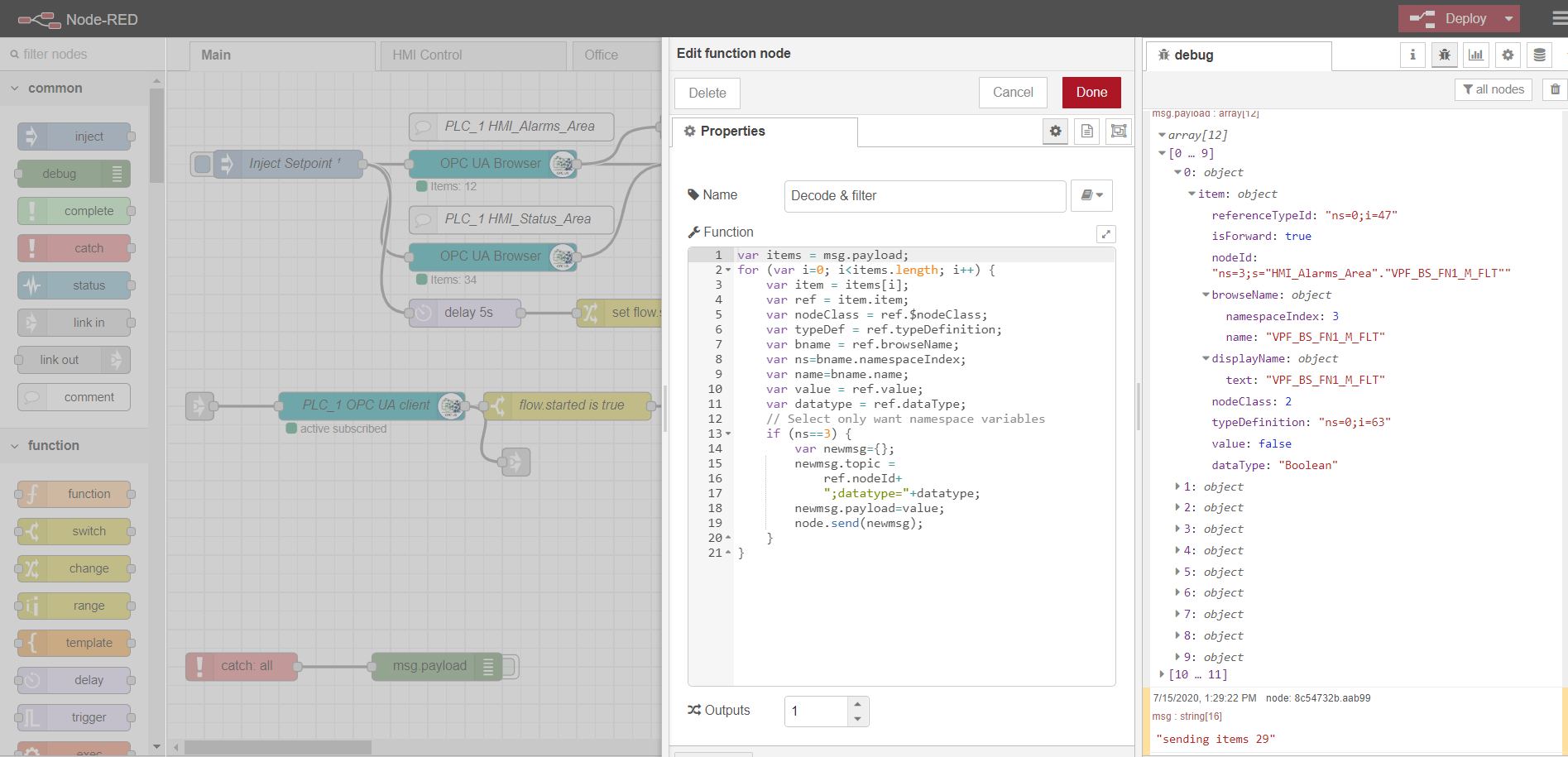
Пример парсинга данных OPC-browser ноды
var items = msg.payload;
for (var i=0; i/ Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
MQTT брокер
В качестве брокера можно использовать любую реализацию. В моем случае уже установлен и настроен Mosquitto брокер
Локальное хранилище данных временных рядов
Данные временного ряда удобно записывать и хранить в NoSql time-series базе данных. Для наших целей удачно подходит
InfluxDB — это база данных временных рядов с открытым исходным кодом, которая является частью стека TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Предназначена для обработки данных с высокой нагрузкой и предоставляет SQL-подобный язык запросов InfluxQL для взаимодействия с данными.
Telegraf — это агент для сбора и отправки метрик и событий в InfluxDB из внешних IoT систем, датчиков и т.п. Настраивается на сбор данных из mqtt топиков.
Kapacitor — это встроенный механизм обработки данных для InfluxDB 1.x и интегрированный компонент в платформу InfluxDB 2.0. Этот сервис можно настроить на мониторинг различных уставок и тревог, а также установить обработчик отправки событий во внешние системы, как Kafkf, email и т.п.
Chronograf — это пользовательский интерфейс и административный компонент платформы InfluxDB 1.x. Используйтся для быстрого создания панелей мониторинга с визуализацией в реальном времени.
Все компоненты стека можно запустить локально или настроить Docker контейнер.
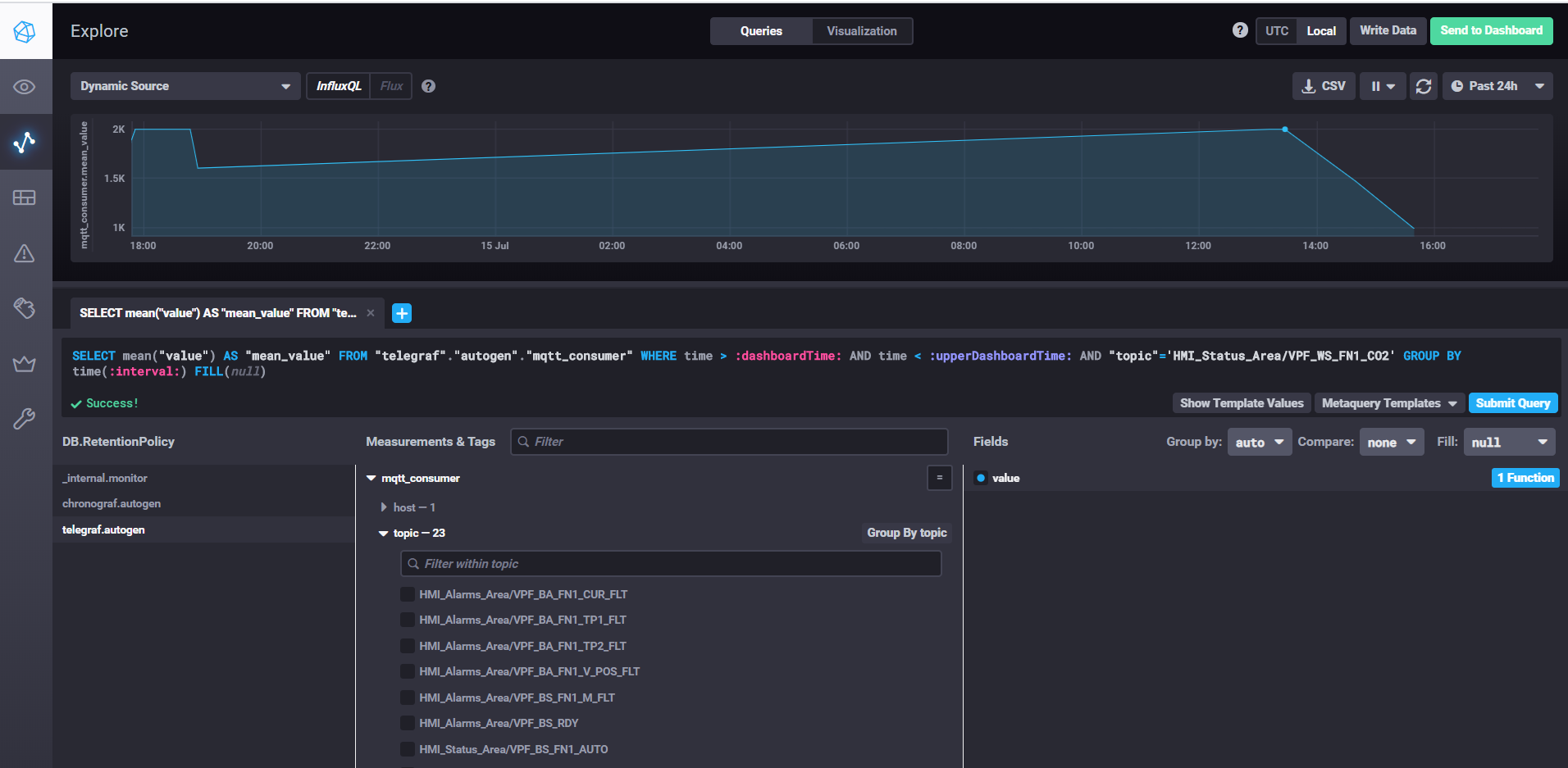
Выборка данных и настройка дашбордов с помощью Chronograf
Для запска InfluxDB достаточно выпонить команду influxd, в настройках influxdb.confможно указать место хранения данных и другие свойства, по умолчанию данных храняться в пользовательском каталоге в .influxdb директории.
Для запуска telegraf необходимо выполнить команду telegraf -config telegraf.conf, где в настройках можно указать источники метрик и событий, в нашем примере для mqtt это выглядит так:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
В свойстве servers указываем url к mqtt брокеру, qos можем оставить 0, если достаточно записывать данные без подтверждения. В свойстве topics указываем маски mqtt топиков, из которых будем читать данные, например HMI_Status_Area/# означает, что мы читаем все топики, имеющие префикс HMI_Status_Area. Таким образом telegraf для каждого топика создаст свою метрику в базе, куда будет писать данные.
Для запуска kapacitor необходимо выполнить команду kapacitord -config kapacitor.conf. Свойства можно оставить по умолчанию и дальнейшие настройки выполнить с помощью Chronograf.
Чтобы запустить chronograf достаточно выполнить одноименную команду chronograf. Веб интерфейс будет доступен
Для настройки уставок и тревог с помощью Kapacitor можно воспользоваться мануалом
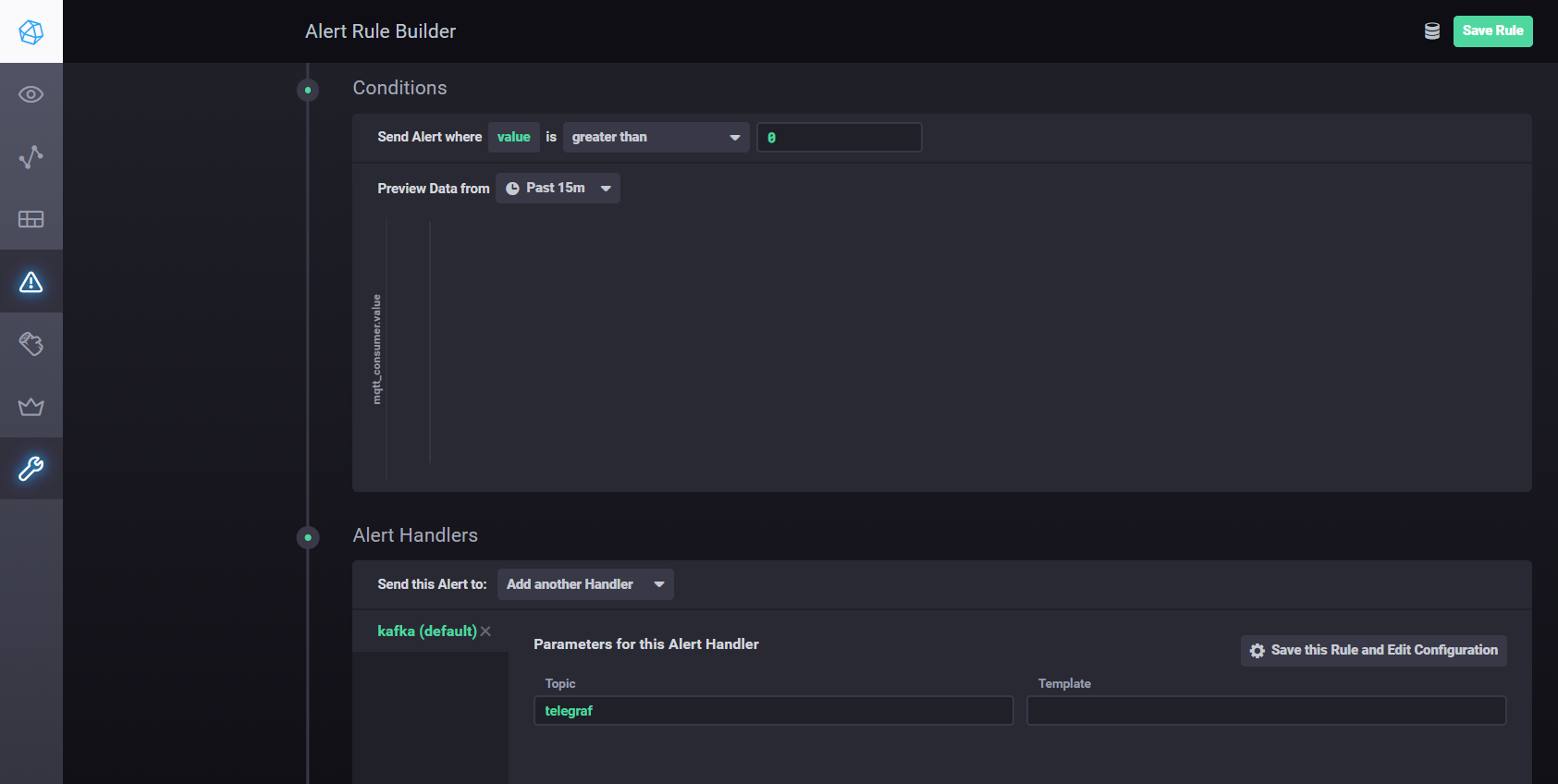
Настройки обработчика Kapacitor
Распределенная потоковая обработка с Apache Kafka
Для предлагаемой архитектуры необходимо отделить сбор данных от обработки, улучшив масштабируемость и независимость уровней. Для достижения этой цели мы можем использовать очередь. В качестве реализации может быть Java Message Service (JMS) или Advanced Message Queuing Protocol (AMQP), но в данном случае будем использовать Apache Kafka. Kafka поддерживается большинством аналитических платформ, имеет очень высокую производительность и масштабируемость, а также имеет хорошую библиотеку потоковой обработки Kafka-streams.
Для взаимодействия к Kafka можно использовать плагин Node-red node-red-contrib-kafka-manager
Для настройки коннектора необходимо в каталок kafka/libs/ скопировать библиотеки kafka-connect-mqtt-1.1-SNAPSHOT.jar и org.eclipse.paho.client.mqttv3-1.0.2.jar (или другую версию). Затем в каталоге /config необходимо создать файл свойств mqtt.properties со следующим содержимым:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Предварительно запустив zookeeper-server и kafka-server можем запустить коннектор с помощью команды:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
Из топика mqtt (mqtt.topic=mqtt) данные будут записываться в Kafka-топик streams-measures (kafka.topic=streams-measures).
В качестве простого примера можно создать maven-проект, используя библиотеку kafka-streams.
С помощью kafka-streams можно создавать различные сервисы и сценарии hot аналитики и потоковой обработки данных.
Например, сравнение текущей температуры с уставкой.
StreamsBuilder builder = new StreamsBuilder();
KStream source = builder.stream("streams-measures");
KStream, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde STRING_SERDE = Serdes.String();
final Serde> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Asset registry
Реестр активов вообще говоря не является структурной составляющей Edge платформы и представляет часть облачной IoT среды. Но в данном примере показано взаимодействие Edge и Cloud.
В качестве asset registry будем использовать популярную IoT платформу ThingsBoard. Интерфейс которой также достаточно интуитивно понятен. Установка возможно с демо-данными. Платформу можно установить локально, в докере или использовать
В набор демо-данных входят тестовые устройства (можно легко создать новое), в которые мы можем отправлять значения. По умолчанию ThingsBoard запускается со своим mqtt брокером, к которому необходимо подключаться и отсылать данные в json формате
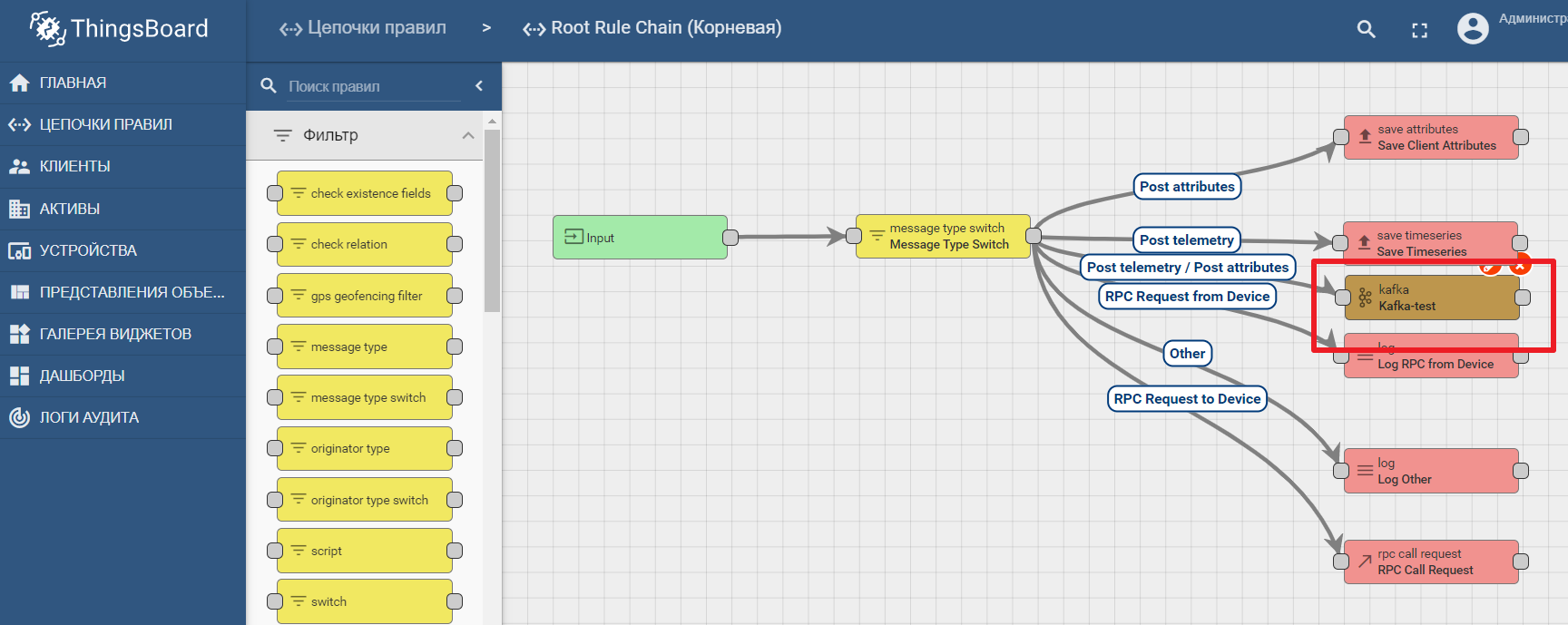
В документации платформы имеется манул по настройке передачи данных и обработке аналитики в Kafka —
Пример использования Kafka ноды в Thingsboard
You must be registered for see links
был краткий обзор промышленного интернета вещей I-IoT и описание платформы граничных вычислений. В этой статье я хочу показать простой пример релизации Edge I-IoT платформы, используя популярные открытые технологии.С архитектурной точки зрения платформа IoT требует решить следующие задачи:
- Объем данных, получаемых, принимаемых и обрабатываемых, требует высокой пропускной способности, хранения и вычислительных возможностей.
- Устройства могут быть распределены по обширной географической области
- Компании требуют, чтобы их архитектура постоянно развивалась, чтобы можно было предлагать новые услуги клиентам.
Одной из особенностей IoT платформы является независимость между объектами и сигналами, что позволяет выполнять параллельные вычисления, повышая производительность.
Данные, поступающие с датчиков, собираются из источников, таких как ПЛК, DCS, микроконтроллеров и т.п и могут храниться во временной области для избежание потери данных из-за проблем с подключением. Данные могут быть временным рядом, такими как событие, полуструктурированные данные, такие как логи и двоичные файлы, или неструктурированные, как изображение. Данные и события временного ряда собираются часто (от каждой секунды до нескольких минут). Затем они отправляются по сети и сохраняются в централизованном озере данных (data lake) и базе данных временных рядов (time-series database TSDB). Data lake может быть облачным, локальным центром обработки данных или сторонней системой хранения.
Данные могут быть немедленно обработаны с использованием анализа потока данных, который называется «hot path», с механизмом проверки правил, основанном на простой или интеллектуальной уставке. Продвинутая аналитика может включать: цифровые близнецы, машинное обучение, глубокое обучение или аналитика на основе физических характеристик. Такая система может обрабатывать большой объем данных (от десяти минут до месяца) с разных датчиков. Эти данные хранятся в промежуточном хранилище. Эта аналитика называется «cold path», и как правило, запускается планировщиком или доступностью данных и требует большого количества вычислительных ресурсов. Продвинутая аналитика часто нуждается в дополнительной информации, такой как модель контролируемой машины и эксплуатационные атрибуты; эта информация содержится в asset registry. Asset registry содержит информацию о типе актива, включая его имя, серийный номер, символическое имя, местоположение, рабочие возможности, историю комплектующих, из которых он состоит, и роль, которую он играет в производственном процессе. В asset registry мы можем хранить список измерений каждого актива, логическое имя, единицу измерения и диапазон границ. В промышленном секторе эта статическая информация важна для правильной аналитической модели.
Причины разработки кастомной платформы:
- Возврат инвестиций: небольшой бюджет;
- Технология: использование технологии независимо от поставщика;
- Конфиденциальность данных;
- Интеграция: необходимость разработки уровня интеграции с новой или устаревшей платформой;
- Другие ограничения;
Cквозной поток данных в I-IoT
Пример кастомной реализации Edge-платформы
На данном рисунке показана реализация следующих звеньев платформы:
- Источник данных: как пример выбран симулятор контроллера Simatic PLCSIM Advanced с активированным OPC сервером, как описано в предыдущей статье.
- В качестве граничного шлюза выбрана популярная платформа Node-Red c установленным плагином node-red-contrib-opcua
You must be registered for see links
- MQTT брокер Mosquitto используется как диспетчер передачи данных между другими звеньями потока.
- Apache Kafka используется как как распределенная потоковая платформа, выполняющая роль аналитики hot path с помощью kafka-streams.
Node-red Edge gateway
В качестве шлюза граничных вычислений будем использовать Node-red, как простую настраиваемую платформу, имеющую множество различных плагинов. Роль промышленного адаптера (Industrial adapter) играет плагин node-red-contrib-opcua. Для множественного сбора данных с контроллера способом подписки используются ноды: OpcUa-Browser и OpcUa-client. В OPC браузер ноде настраивается url OPC-сервера (endpoint) и топик, в котором указано пространство имен и имя читаемого блока данных, например ns=3;s=«HMI_Alarms_Area». В OPC-клиент ноде также указывается url OPC-сервера, в качестве действия (Action) устанавливается SUBSCRIBE и интервал обновления данных.
Node-red main flow
Настройка ноды OPC-browser
Настройка ноды OPC-client
Для того, чтобы выполнилась подписка на чтения множественных данных, необходимо подготовить и загрузить топики тегов чтения с контроллера, согласно OPC протокола. Для этого вначале используется inject нода с чекбоксом only once, которая тригерит единократное чтения блоков данных, указанных в нодах OPC-браузера. Затем данные обрабатываются функцией Decode&filter. После чего нода OPC-клиента подписывается и читает изменяющиеся данные с контроллера. Дальнейшая обработка потока зависит от конкретной реализации и требований. В своем примере я обрабатываю данные для дальнейшей отсылки их в MQTT брокер на разные топики.
Вкладки HMI control и Office представляют собой простую реализуцию HMI на базе Scadavis.io и node-red dashboard, как описано
You must be registered for see links
.
Пример парсинга данных OPC-browser ноды
var items = msg.payload;
for (var i=0; i/ Select only want namespace variables
if (ns==3) {
var newmsg={};
newmsg.topic =
ref.nodeId+
";datatype="+datatype;
newmsg.payload=value;
node.send(newmsg);
}
}
MQTT брокер
В качестве брокера можно использовать любую реализацию. В моем случае уже установлен и настроен Mosquitto брокер
You must be registered for see links
. Брокер выполняет функцию транспорта данных между Edge gateway и другими участниками платформы. Есть примеры с балансировкой нагрузки и распределенной архитектурой, например
You must be registered for see links
. В данном случае ограничимся одним mqtt брокером с передачей данных без шифрования.Локальное хранилище данных временных рядов
Данные временного ряда удобно записывать и хранить в NoSql time-series базе данных. Для наших целей удачно подходит
You must be registered for see links
. Нам необходимо четыре сервиса из этого стека:InfluxDB — это база данных временных рядов с открытым исходным кодом, которая является частью стека TICK (Telegraf, InfluxDB, Chronograf, Kapacitor). Предназначена для обработки данных с высокой нагрузкой и предоставляет SQL-подобный язык запросов InfluxQL для взаимодействия с данными.
Telegraf — это агент для сбора и отправки метрик и событий в InfluxDB из внешних IoT систем, датчиков и т.п. Настраивается на сбор данных из mqtt топиков.
Kapacitor — это встроенный механизм обработки данных для InfluxDB 1.x и интегрированный компонент в платформу InfluxDB 2.0. Этот сервис можно настроить на мониторинг различных уставок и тревог, а также установить обработчик отправки событий во внешние системы, как Kafkf, email и т.п.
Chronograf — это пользовательский интерфейс и административный компонент платформы InfluxDB 1.x. Используйтся для быстрого создания панелей мониторинга с визуализацией в реальном времени.
Все компоненты стека можно запустить локально или настроить Docker контейнер.
Выборка данных и настройка дашбордов с помощью Chronograf
Для запска InfluxDB достаточно выпонить команду influxd, в настройках influxdb.confможно указать место хранения данных и другие свойства, по умолчанию данных храняться в пользовательском каталоге в .influxdb директории.
Для запуска telegraf необходимо выполнить команду telegraf -config telegraf.conf, где в настройках можно указать источники метрик и событий, в нашем примере для mqtt это выглядит так:
# # Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
servers = ["tcp://192.168.1.107:1883"]
qos = 0
topics = ["HMI_Status_Area/#", "HMI_Alarms_Area/#"]
data_format = "value"
data_type = "float"
В свойстве servers указываем url к mqtt брокеру, qos можем оставить 0, если достаточно записывать данные без подтверждения. В свойстве topics указываем маски mqtt топиков, из которых будем читать данные, например HMI_Status_Area/# означает, что мы читаем все топики, имеющие префикс HMI_Status_Area. Таким образом telegraf для каждого топика создаст свою метрику в базе, куда будет писать данные.
Для запуска kapacitor необходимо выполнить команду kapacitord -config kapacitor.conf. Свойства можно оставить по умолчанию и дальнейшие настройки выполнить с помощью Chronograf.
Чтобы запустить chronograf достаточно выполнить одноименную команду chronograf. Веб интерфейс будет доступен
You must be registered for see links
:8888/Для настройки уставок и тревог с помощью Kapacitor можно воспользоваться мануалом
You must be registered for see links
. В кратце – нужно перейти во вкладку Alerting в Chronograf и создать новое правило с помощью кнопки Build Alert Rule, интерфейс интуитивно понятен, все выполняется визуально. Для настройки отсылки результатов обработки в kafka (и др.) необходимо добавить обработчик в разделе ConditionsНастройки обработчика Kapacitor
Распределенная потоковая обработка с Apache Kafka
Для предлагаемой архитектуры необходимо отделить сбор данных от обработки, улучшив масштабируемость и независимость уровней. Для достижения этой цели мы можем использовать очередь. В качестве реализации может быть Java Message Service (JMS) или Advanced Message Queuing Protocol (AMQP), но в данном случае будем использовать Apache Kafka. Kafka поддерживается большинством аналитических платформ, имеет очень высокую производительность и масштабируемость, а также имеет хорошую библиотеку потоковой обработки Kafka-streams.
Для взаимодействия к Kafka можно использовать плагин Node-red node-red-contrib-kafka-manager
You must be registered for see links
. Но учитываю разделения сбора от обработки данных, установим плагин MQTT, который подписывается на топики Mosquitto. Плагин MQTT доступен по ссылке
You must be registered for see links
. Для настройки коннектора необходимо в каталок kafka/libs/ скопировать библиотеки kafka-connect-mqtt-1.1-SNAPSHOT.jar и org.eclipse.paho.client.mqttv3-1.0.2.jar (или другую версию). Затем в каталоге /config необходимо создать файл свойств mqtt.properties со следующим содержимым:
name=mqtt
connector.class=com.evokly.kafka.connect.mqtt.MqttSourceConnector
tasks.max=1
kafka.topic=streams-measures
mqtt.client_id=mqtt-kafka-123456789
mqtt.clean_session=true
mqtt.connection_timeout=30
mqtt.keep_alive_interval=60
mqtt.server_uris=tcp://192.168.1.107:1883
mqtt.topic=mqtt
Предварительно запустив zookeeper-server и kafka-server можем запустить коннектор с помощью команды:
connect-standalone.bat …\config\connect-standalone.properties …\config\mqtt.properties
Из топика mqtt (mqtt.topic=mqtt) данные будут записываться в Kafka-топик streams-measures (kafka.topic=streams-measures).
В качестве простого примера можно создать maven-проект, используя библиотеку kafka-streams.
С помощью kafka-streams можно создавать различные сервисы и сценарии hot аналитики и потоковой обработки данных.
Например, сравнение текущей температуры с уставкой.
StreamsBuilder builder = new StreamsBuilder();
KStream source = builder.stream("streams-measures");
KStream, String> max = source
.selectKey((String key, String value) -> {
return getKey(key, value);
}
)
.groupByKey()
.windowedBy(TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)))
.reduce((String value1, String value2) -> {
double v1=getValue(value1);
double v2=getValue(value2);
if ( v1 > v2)
return value1;
else
return value2;
}
)
.toStream()
.filter((Windowed key, String value) -> {
String measure = tagMapping.get(key.key());
double parsedValue = getValue(value);
if (measure!=null) {
Double threshold = excursion.get(measure);
if (threshold!=null) {
if(parsedValue > threshold) {
log.info(String.format("%s : %s; Threshold: %s", key.key(), parsedValue, threshold));
return true;
}
return false;
}
} else {
log.severe("UNKNOWN MEASURE! Did you mapped? : " + key.key());
}
return false;
}
);
final Serde STRING_SERDE = Serdes.String();
final Serde> windowedSerde = Serdes.serdeFrom(
new TimeWindowedSerializer<>(STRING_SERDE.serializer()),
new TimeWindowedDeserializer<>(STRING_SERDE.deserializer(), TimeWindows.of(Duration.ofSeconds(WINDOW_SIZE)).size()));
// the output
max.to("excursion", Produced.with(windowedSerde, Serdes.String()));
Asset registry
Реестр активов вообще говоря не является структурной составляющей Edge платформы и представляет часть облачной IoT среды. Но в данном примере показано взаимодействие Edge и Cloud.
В качестве asset registry будем использовать популярную IoT платформу ThingsBoard. Интерфейс которой также достаточно интуитивно понятен. Установка возможно с демо-данными. Платформу можно установить локально, в докере или использовать
You must be registered for see links
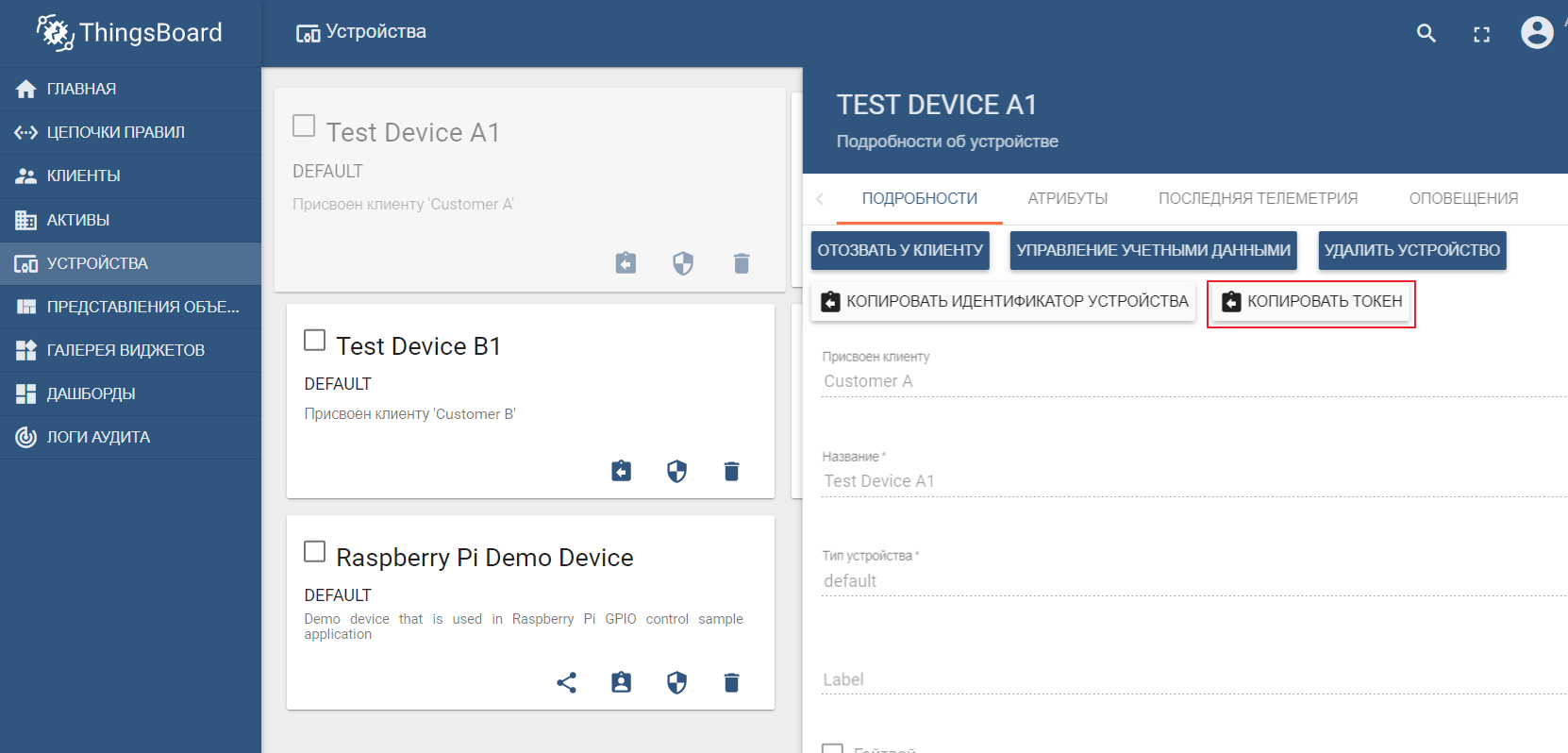
.В набор демо-данных входят тестовые устройства (можно легко создать новое), в которые мы можем отправлять значения. По умолчанию ThingsBoard запускается со своим mqtt брокером, к которому необходимо подключаться и отсылать данные в json формате
You must be registered for see links
. Допустим, мы хотим отсылать данные в ThingsBoard от устройства TEST DEVICE A1. Для этого нам необходимо подключиться к ThingBoard брокеру по адресу localhost:1883, используя A1_TEST_TOKEN в качестве логина, который можно скопировать из настроек устройства. После чего можем публиковать данные в топик v1/devices/me/telemetry: {“temperature”:26}
В документации платформы имеется манул по настройке передачи данных и обработке аналитики в Kafka —
You must be registered for see links
Пример использования Kafka ноды в Thingsboard