



Онлайн
Alvaros
.
- Регистрация
- 14.05.16
- Сообщения
- 21.452
- Реакции
- 101
- Репутация
- 204
You must be registered for see links
You must be registered for see links
В этой статье вы узнаете:
-О соревновании ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
-О том, какие существуют архитектуры CNN:
1) LeNet-5
2) AlexNet
3) VGGNet
4) GoogLeNet
5) ResNet
-О том, какие проблемы появлялись с новыми архитектурами сетей, как они решались последующими:
1) vanishing gradient problem
2) exploding gradient problem
ILSVRC
You must be registered for see links
— это такое ежегодное соревнование, на котором ресечеры сравнивают свои сетки в задачах обнаружения и классификации объектов на фотографиях.Это соревнование являлось толчком для развития:
-Архитектур нейронных сетей
-Различных методов и практик, которыми пользуются и по сей день
По этому графику видно, как развивались алгоритмы классификации с течением времени:
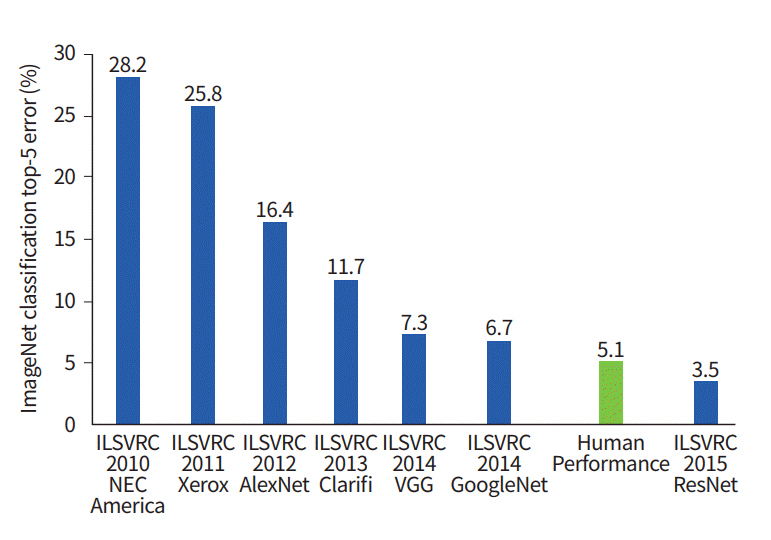
По оси x — года и алгоритмы (с 2012 года — сверточные нейронные сети).
По оси y — процент ошибок на выборке из top-5 error.
Top-5 error — это способ оценивания модели: модель возвращает некое распределение вероятностей и если среди топ-5 вероятностей есть истинное значение (метка класса) класса, то ответ модели считается правильным. Соответственно, (1 — top-1 error) — это всем знакомая точность (accuracy).
Архитектуры CNN
LeNet-5
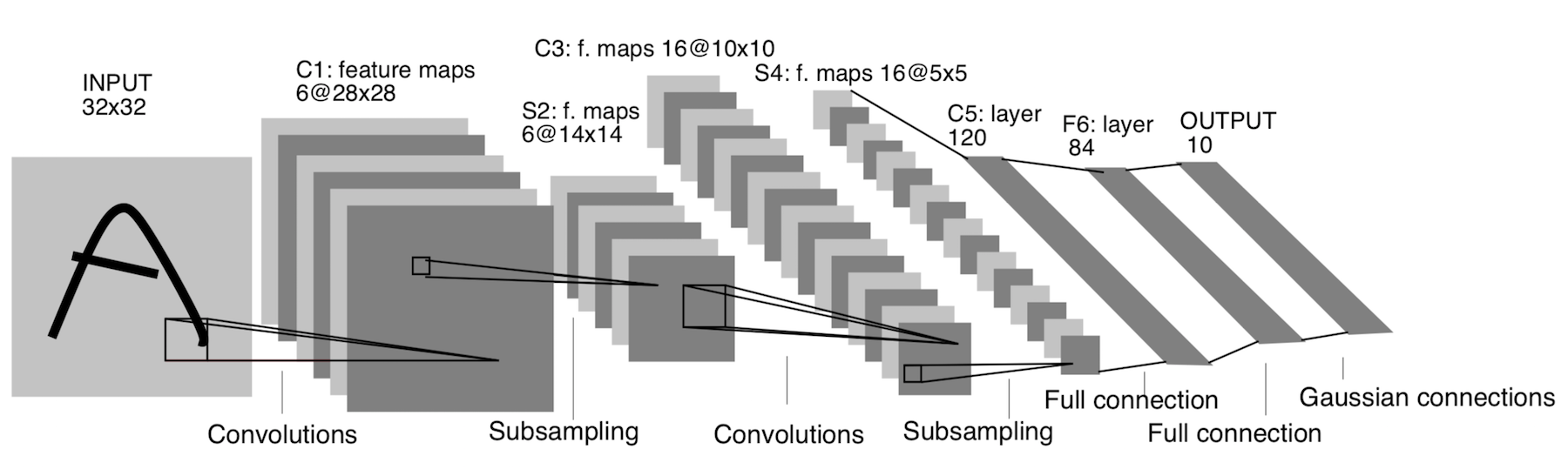
Появилась аж в 1998 году!!! Была предназначена для распознавания рукописных букв и цифр. Под subsampling (понижение размерности) здесь подразумевается pooling-слой.
Архитектура:
CONV 5x5, stride = 1
POOL 2x2, stride = 2
CONV 5x5, stride = 1
POOL 5x5, stride = 2
FC (120, 84)
FC (84, 10)
Сейчас эта архитектура имеет только историческую значимость. Подобную архитектуру легко имплементировать «ручками» в любом современном фреймворке для глубокого обучения.
AlexNet

Картинка не дублируется. Так изображена архитектура, потому что архитектура AlexNet тогда не влезала на одно устройство GPU, поэтому «половина» сети работала на одной GPU, а вторая — на другой.
Появилась в 2012 году. С нее и начался прорыв в том самом ILSVRC — она победила все stat-of-art модели того времени. После этого люди поняли, что нейронные сети действительно работают
")
Архитектура более конкретно:

Если приглядеться на архитектуру AlexNet, то можно увидеть, что за 14 лет (с появления LeNet-5) не произошло почти никаких изменений, кроме кол-ва слоев.
Важно:
-Мы берем нашу исходную картинку 227x227x3 и понижаем ее размерность (по высоте и ширине), но увеличиваем кол-во каналов. Такая часть архитектуры «кодирует» изначальное представление объекта (encoder).
-Впервые была применена функция активации ReLU. Подробнее про ReLu и другие функции активаций можно почитать
You must be registered for see links
.-60 миллионов обучаемых параметров.
-Основная часть обучаемых параметров приходится на полносвязные слои.
Примечания:
-Local Response Norm — это способ нормализации, который использовался в сетях того времени. Сейчас используют
You must be registered for see links
.-Слева указано кол-во обучаемых параметров в том или ином слое, справа — кол-во
You must be registered for see links
, требуемых на выполнение.-Запись вида FC 4096 означает, что полносвязный (Fully-connected) слой имеет 4096 выходных нейронов.
-Запись вида Max Pool 3x3s2 означает, что слой пулинга имеет фильтр 3x3, шаг = 2.
-Запись вида Conv 11x11s4, 96 означает, что слой свертки имеет фильтр 11x11xNc, шаг = 4, кол-во таких фильтров равно 96. Теперь кол-во таких фильтров — это кол-во каналов для следующего слоя (то самое Nc). Считаем, что начальное изображение имеет три канала (R, G и B).
VGGNet
Архитектура:
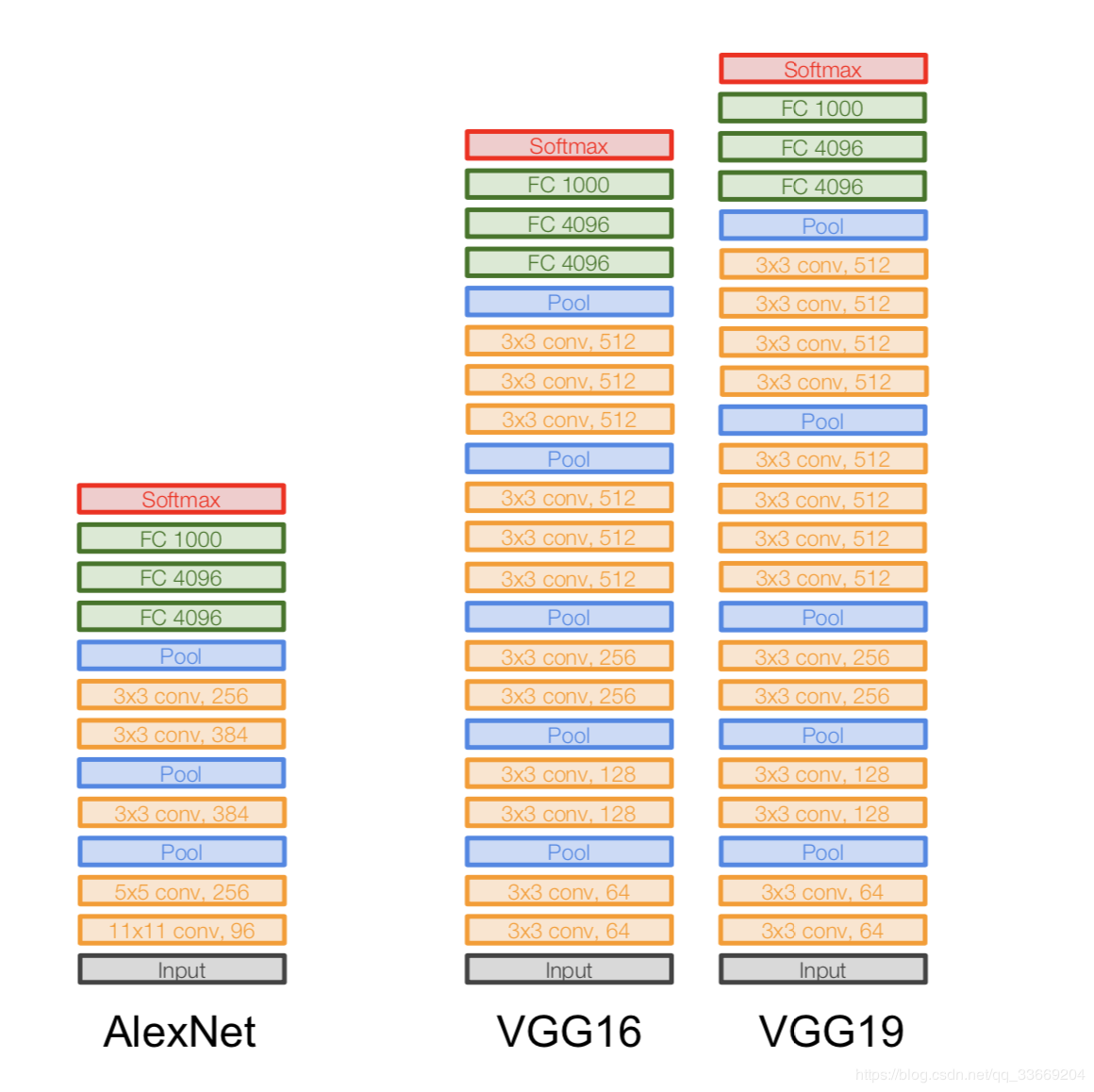
Появилась в 2014 году.
Две версии — VGG16 и VGG19. Основная идея — использовать вместо больших сверток (11x11 и 5x5) маленькие свертки (3x3). Интуиция в использовании больших сверток простая — мы хотим получать больше информации от соседних пикселей, но гораздо лучше использовать маленькие фильтры чаще.
И вот почему:
-Каждый последующий слой свертки обладает информацией о предыдущем. И чем сильнее мы углубляемся, тем больше информации последний сверточный слой содержит о первом. Т.е. мы добились того, чего хотели добиться большими свертками, но в малом количестве.
-Мы слабее уменьшаем размерность нашего изображения => можем применять больше сверток.
-Больше сверток — больше активаций, больше активаций — больше нелинейности, а нелинейность — это как раз то, чего мы добиваемся.
Важно:
-Во время обучения нейронной сети для алгоритма обратного распространения ошибки важно сохранять представления объекта (для нас — исходного изображения) на всех этапах (свертках, пулингах) прямого распространения (forward pass — это когда мы подаем на вход картинку и движемся к выходу, к результату). Такое представления объекта может дорого стоить в плане памяти. Взгляните:
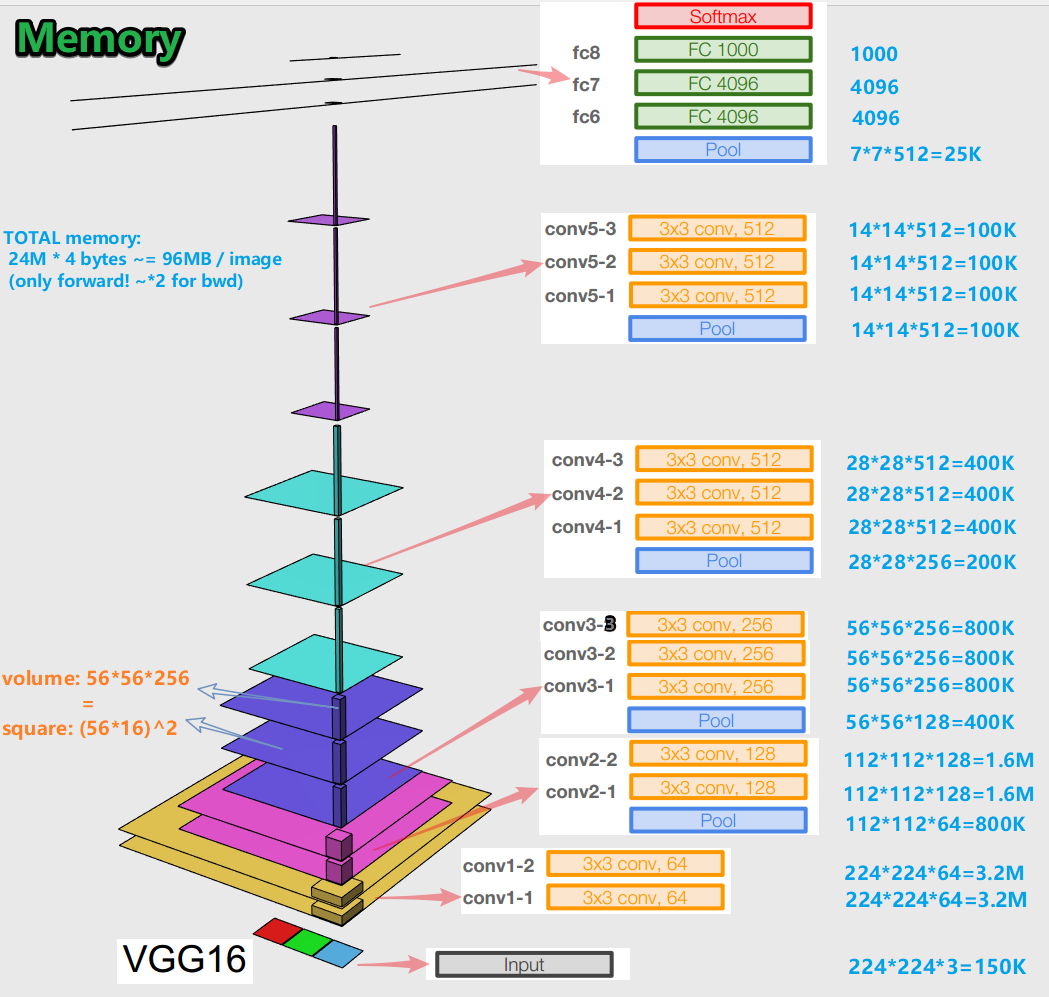
Получается примерно 96 МБ на изображение — и это только для forward pass'а. Для backward pass'a (bwd на картинке) — во время вычисления градиентов — примерно в два раза больше. Выходит такая интересная картина: наибольшее число обучаемых параметров расположено в полносвязных слоях, а наибольшую память занимают представления объекта после сверточных и пулинговых слоев. С — синергия.
-Сеть имеет 138 миллионов обучаемых параметров в вариации 16-ти слоев и 143 миллиона параметров в вариации 19-ти слоев.
GoogLeNet
Архитектура:
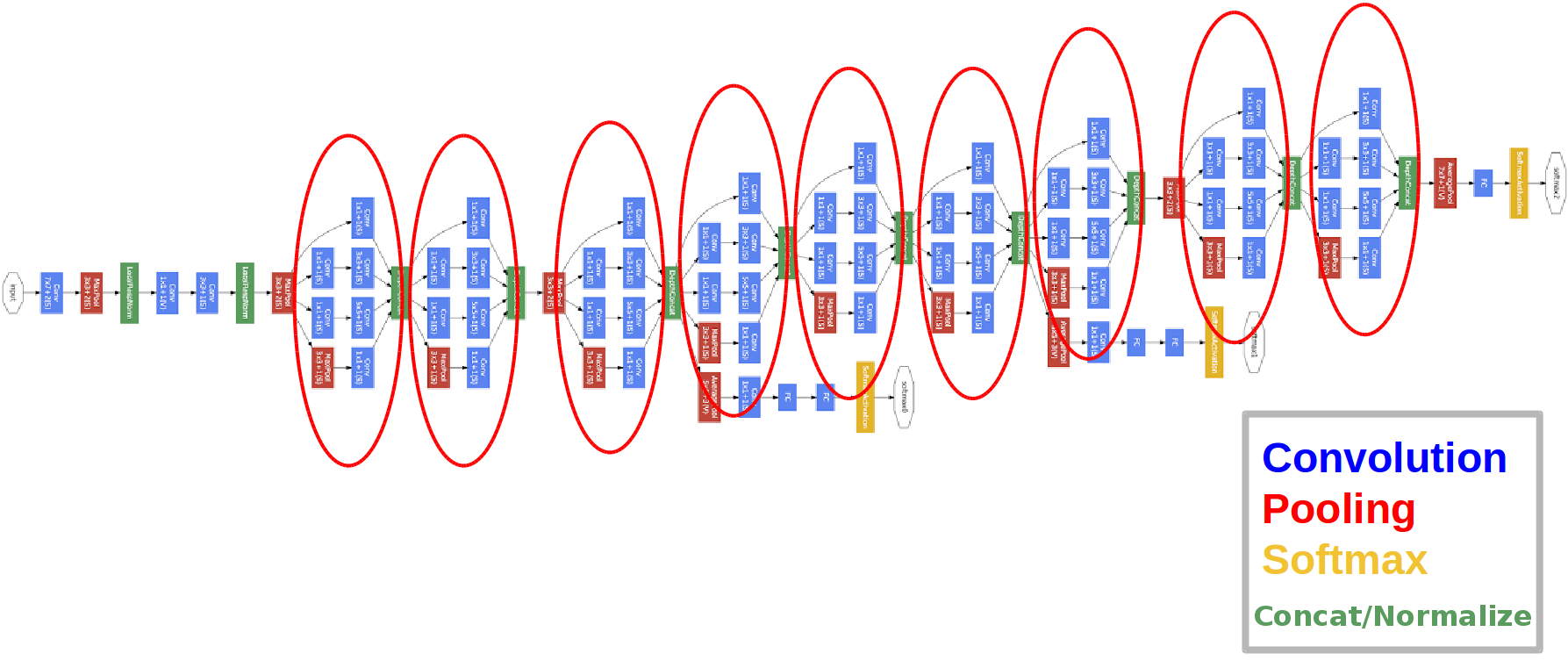
Появилась в 2014 году.
Красные кружочки — это так называемый Inception module.
Давайте взглянем на него поближе:
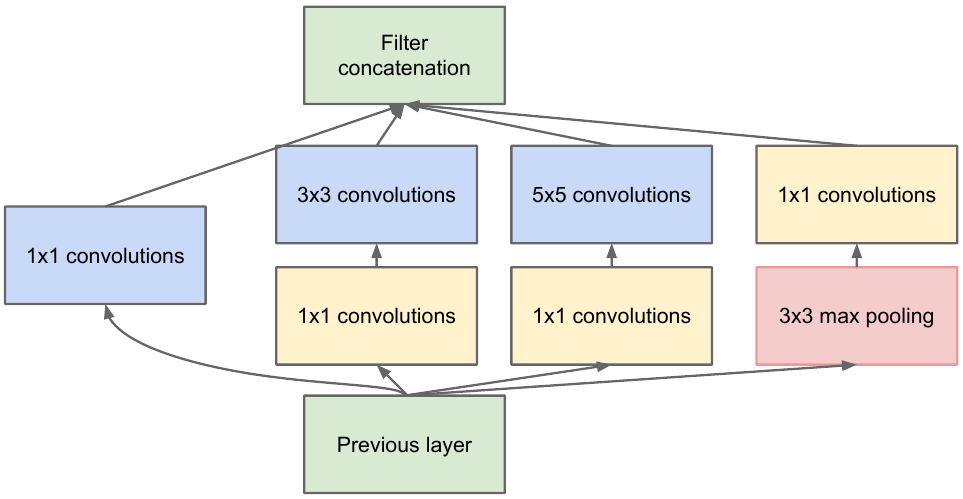
Мы берем карту признаков (feature map) с предыдущего слоя, применяем к ней какое-то количество сверток с разными фильтрами, потом конкатенируем полученное. Интуиция простая: мы хотим получить различные представления нашей карты признаков, используя фильтры разных размеров. Свертки 1x1 используются для того, чтобы не так сильно наращивать кол-во каналов после каждого такого inception-блока. Т.е. когда у карты признаков большое кол-во каналов, и хотят уменьшить это кол-во, не изменяя высоту и ширину карты признаков, используют свертку размерности 1x1.
Также в сети присутствуют три блока-классификатора, вот так выглядит один из них (тот что справа для нас):

С помощью такой конструкции градиент «лучше» доходит от выходных слоев до входных во время обратного распространения ошибки.
Зачем нужны еще два лишних выхода сети? Дело все в так называемой проблеме затухающего градиента (vanishing gradient problem):
Суть в том, что при выполнении обратного распространения ошибки градиент банально стремится к нулю. Чем глубже сеть — тем она более подвержена этому явлению. Почему так происходит? Когда мы выполняем backward pass, мы идем от выхода ко входу, вычисляя градиенты сложных функций. Производная сложной функции (
You must be registered for see links
) — это, по сути, умножение. И вот так, умножая какие-то значения по пути от выхода ко входу, мы встречаем числа, которые близки к нулю, и, как следствие, веса нейронной сети практически не обновляются. Частично это проблема функций активаций типа sigmoid, у которых выход лежит в каком-то фиксированном диапазоне. Ну и частично эта проблема решается путем использования функции активации ReLu. Почему частично? Потому что никто не дает гарантии на значения обучаемых параметров и представления входного объекта во всех картах признаков.Важно:
-Сеть имеет 22 слоя (это чуть больше, чем имеет предыдущая сеть).
-Число обучаемых параметров равно пяти миллионам, что в разы и разы меньше, чем у предыдущих двух сетей.
-Появление сверток 1x1.
-Используются Inception блоки.
-Вместо полносвязных слоев теперь свертки 1x1, которые понижают глубину и, как следствие, понижают размерность полносвязных слоев и так называемый global avegare pooling (подробнее можно прочитуть
You must be registered for see links
).-Архитектура имеет 3 выхода(итоговый ответ взвешивается).
ResNet
Архитектура (вариант ResNet-34):
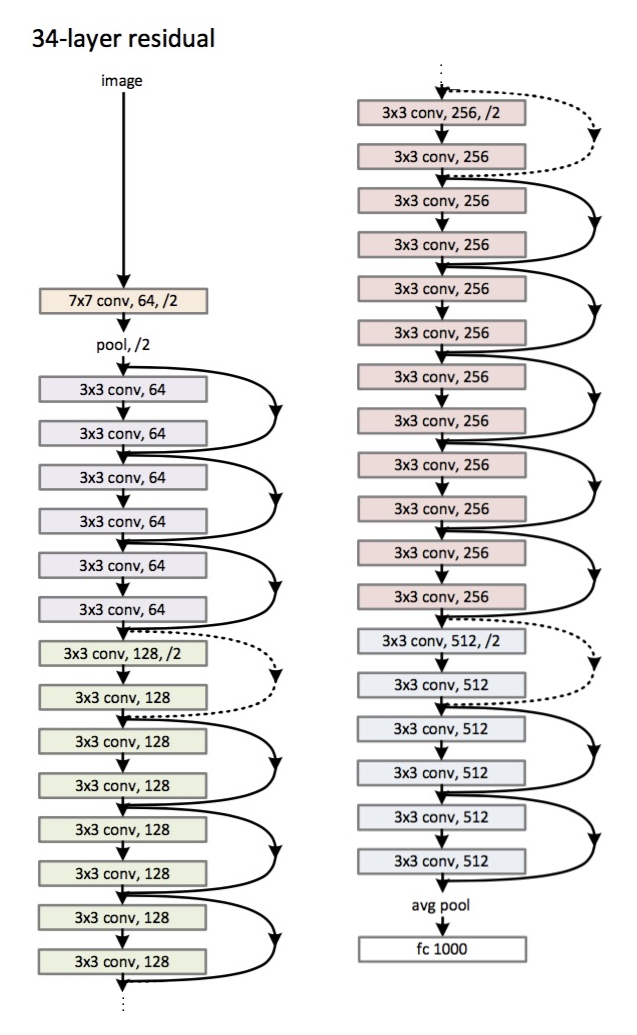
Появилась в 2015 году.
Основным новшеством стало большое количество слоев и, так называемые, residual блоки. Эти блоки используются в качестве борьбы с проблемой затухающего градиента. Связь между такими residual-блоками называется shortcut (стрелочки на картинке). Теперь по этим шорткатам градиент и будет доходить до всех нужных параметров, тем самым обучая сеть
Важно:
-Вместо полносвязных слоев — average global pooling.
-Residual-блоки.
-Сеть превзошла человека в распознавании образов на датасете ImageNet (top-5 error).
-Впервые использован batch-normalization.
-Используется техника инициализации весов (интуиция: из определенной инициализации весов сеть сходится (обучается) быстрее и лучше).
-Максимальная глубина — 152 слоя!
Небольшое отступление
Проблема затухающего градиента актуальна для всех глубоких нейронных сетей.
Существует и ее антагонист — проблема взрывающегося градиента (exploding gradient problem), которая также актуальная для всех глубоких нейронных сетей. Суть понятная из названия — градиент становится слишком большим, что вызывает NaN (not a number, бесконечность). Решение очевидно — ограничить значение градиента, в противном случае — уменьшить его значение (нормировать). Такая техника называется «clipping».
Заключение
В 2019-м году появилась
You must be registered for see links
о новом семействе архитектур — EfficientNet.Следить за последними трендами в различных задачах и областях, связанными с Machine Learning, рекомендую
You must be registered for see links
. На этом ресурсе можно выбрать задачу(например, image classification) и датасет(например, ImageNet) и посмотреть на качество тех или иных архитектур, дополнительную информацию о них. Например, сетка FixEfficientNet-L2 занимает почетное первое место
You must be registered for see links
(top-1 accuracy).В следующих статьях поговорим про transfer learning, object detection, segmentation.