



Онлайн
Alvaros
.
- Регистрация
- 14.05.16
- Сообщения
- 21.452
- Реакции
- 101
- Репутация
- 204
Все большую популярность набирает NiFi и с каждым новым релизом он получает все больше инструментов для работы с данными. Тем не менее, может появиться необходимость в собственном инструменте для решения какой-то специфичной задачи.
Apache Nifi имеет в базовой поставке более 300 процессоров.
NiFi Processor это основной строительный блок для создания dataflow в экосистеме NiFi. Процессоры предоставляют интерфейс, через который NiFi обеспечивает доступ к flowfile, его атрибутам и содержимому. Собственный кастомный процессор позволит сэкономить силы, время и внимание пользователей, так как вместо множества простейших элементов-процессоров будет отображаться в интерфейсе и выполняться всего один (ну или сколько напишете). Так же, как и стандартные процессоры, кастомный процессор позволяет выполнять различные операции и обрабатывать содержимое flowfile. Сегодня мы поговорим о стандартных инструментах для расширения функционала.
ExecuteScript
ExecuteScript – это универсальный процессор, который предназначен для реализации бизнес- логики на языке программирования (Groovy, Jython, Javascript, JRuby). Такой подход позволяет быстро получить нужную функциональность. Для обеспечения доступа к компонентам NiFi в скрипте есть возможность использовать следующие переменные:
Session: переменная типа org.apache.nifi.processor.ProcessSession. Переменная позволяет выполнять операции с flowfile, такими как create(), putAttribute() и Transfer(), а также read() и write().
Context: org.apache.nifi.processor.ProcessContext. Его можно использовать для получения свойств процессора, отношений, служб контроллера и StateManager.
REL_SUCCESS: Отношение «успех».
REL_FAILURE: Отношение «сбой»
Dynamic Properties: Динамические свойства, определенные в ExecuteScript, передаются механизму сценариев в виде переменных, установленные как объект PropertyValue. Это позволяет получить значение свойства, привести значение к соответствующему типу данных, например, логическому и т. д.
Для использования достаточно выбрать Script Engine и указать расположение файла Script File с нашим скриптом или сам скрипт Script Body.
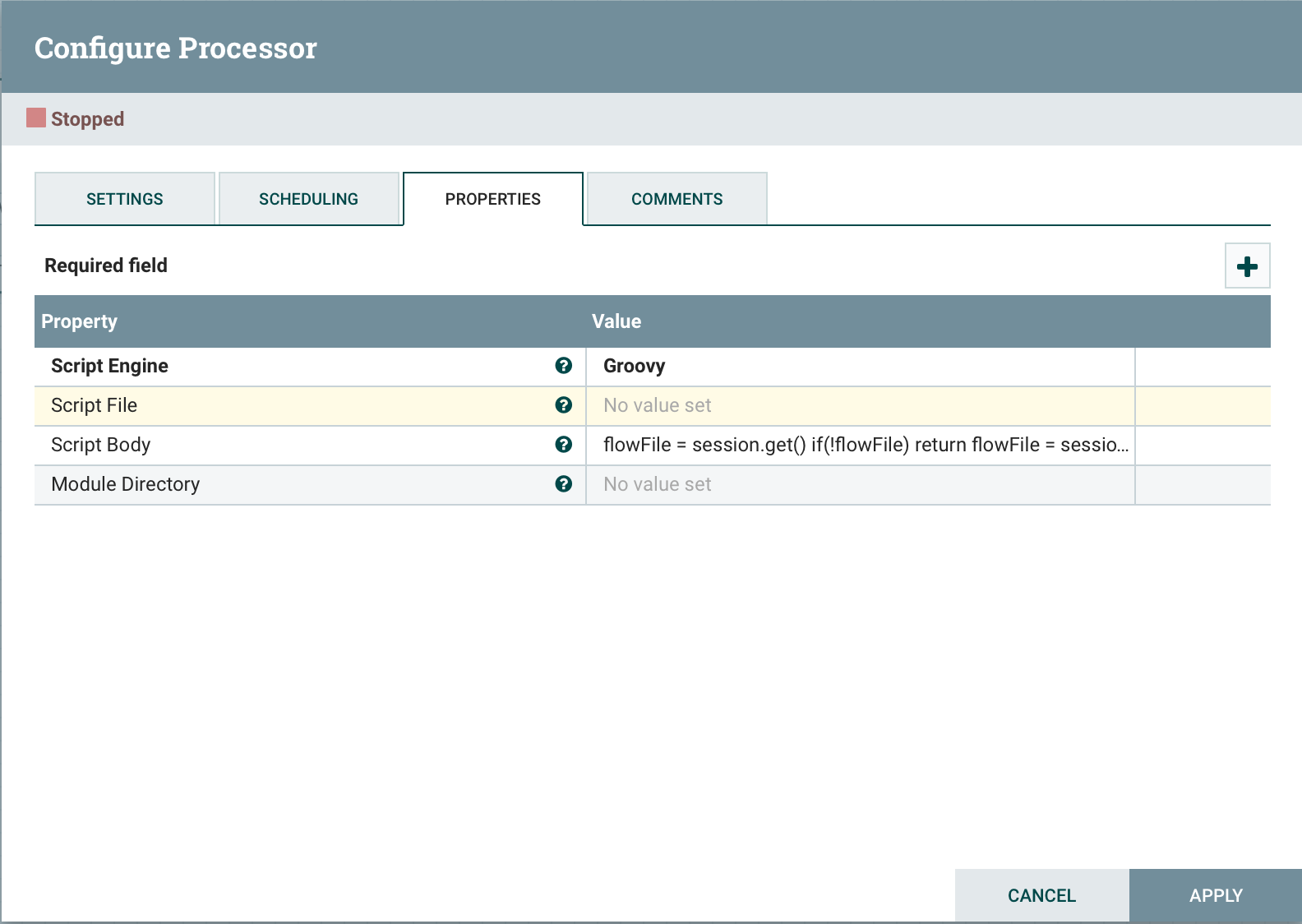
Рассмотрим парочку примеров:
получить один файл потока из очереди
flowFile = session.get()
if(!flowFile) return
Сгенерировать новый FlowFile
flowFile = session.create()
// Additional processing here
Добавить атрибут к FlowFile
flowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Извлечь и обработать все атрибуты.
flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Логгер
log.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
В ExecuteScript есть можно использовать расширенные возможности, подробнее об этом можно почитать в статье ExecuteScript Cookbook.
ExecuteGroovyScript
ExecuteGroovyScript имеет такой же функционал, что и ExecuteScript, но вместо зоопарка допустимых языков можно использовать только один – groovy. Главное преимущество этого процессора – это более удобное использование служб сервисов. Помимо стандартного набора переменных Session, Context и т.д. можно определить динамические свойства с префиксом CTL и SQL. Начиная с версии 1.11 появилась поддержка RecordReader и Record Writer. Все свойства представляют собой HashMap, у которого в качестве ключа используется «Имя сервиса», а значение – это конкретный объект в зависимости от свойства:
RecordWriter HashMap
RecordReader HashMap
SQL HashMap
CTL HashMap
Данная информация уже облегчает жизнь, т.к. мы можем заглянуть в исходники или найти документацию по конкретному классу.
Работа с базой данных
Если определить свойство SQL.DB и связать DBCPService, то мы получим доступ к свойству из кода SQL.DB.rows('select * from table')
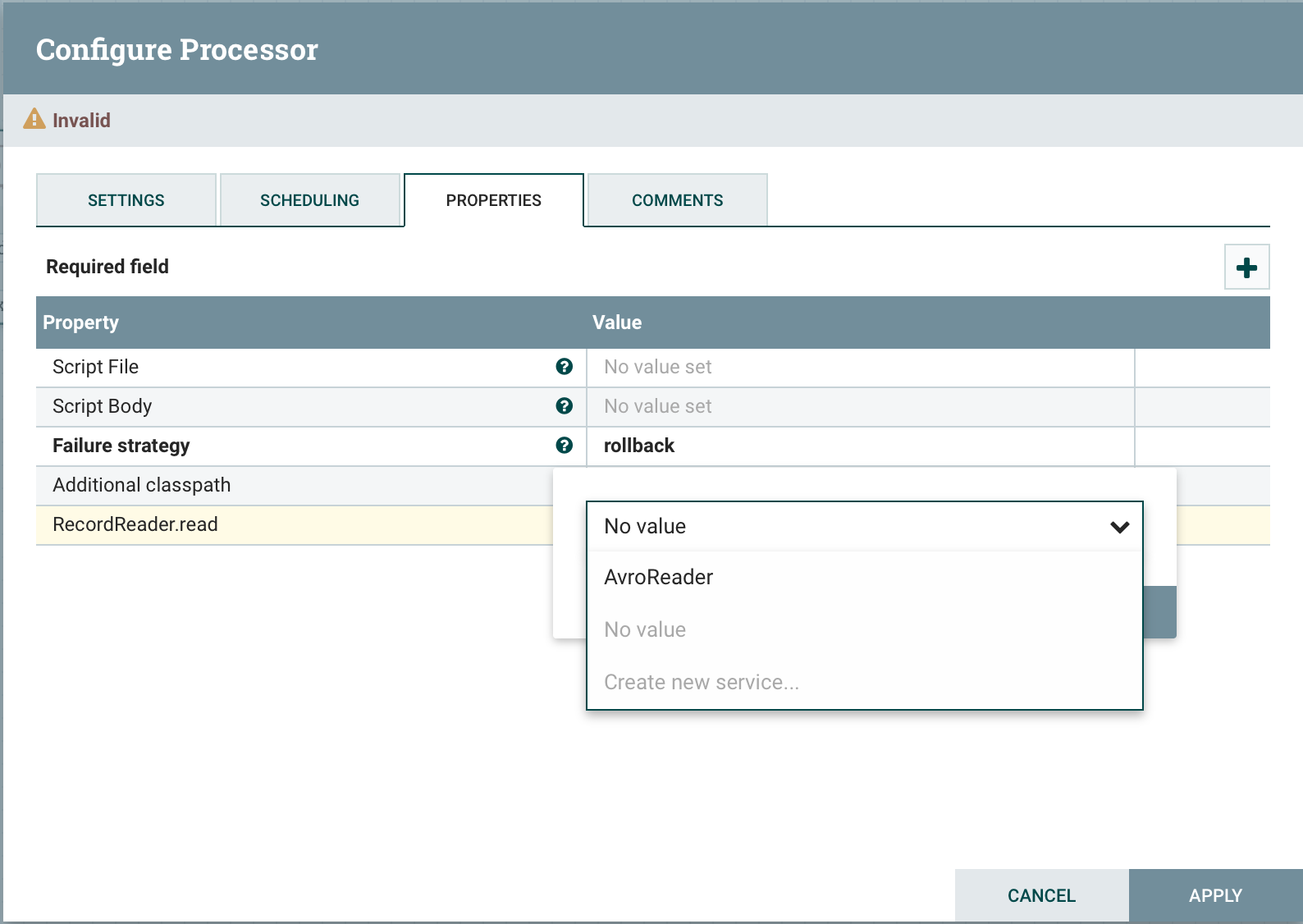
Процессор автоматически принимает соединение от службы dbcp перед выполнением и обрабатывает транзакцию. Транзакции базы данных автоматически откатываются при возникновении ошибки и фиксируются в случае успеха. В ExecuteGroovyScript можно перехватывать события start и stop, реализовав соответствующие статические методы.
import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS code>
InvokeScriptedProcessor
Еще один интересный процессор. Для его использования нужно объявить класс, который реализовывает интерфейс implements, и определить переменную processor. Можно определить любые PropertyDescriptor или Relationship, также получить доступ к родительскому ComponentLog'у и определить методы void onScheduled(ProcessContext context) и void onStopped(ProcessContext context). Эти методы будут вызваны при наступлении события запуска по расписанию в NiFi (onScheduled) и при остановке (onScheduled).
class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List
getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Логику надо реализовать в методе void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
Описывать все методы, декларированные в интерфейсе излишне, так что обойдемся одним абстрактным классом, в котором объявим следующий метод:
abstract void executeScript(ProcessContext context, ProcessSession session)
Метод мы будем вызывать в
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List
getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Теперь объявим класс-наследник BaseGroovyProcessorи опишем наш executeScript, также добавим Relationship RELSUCCESS и RELFAILURE.
import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
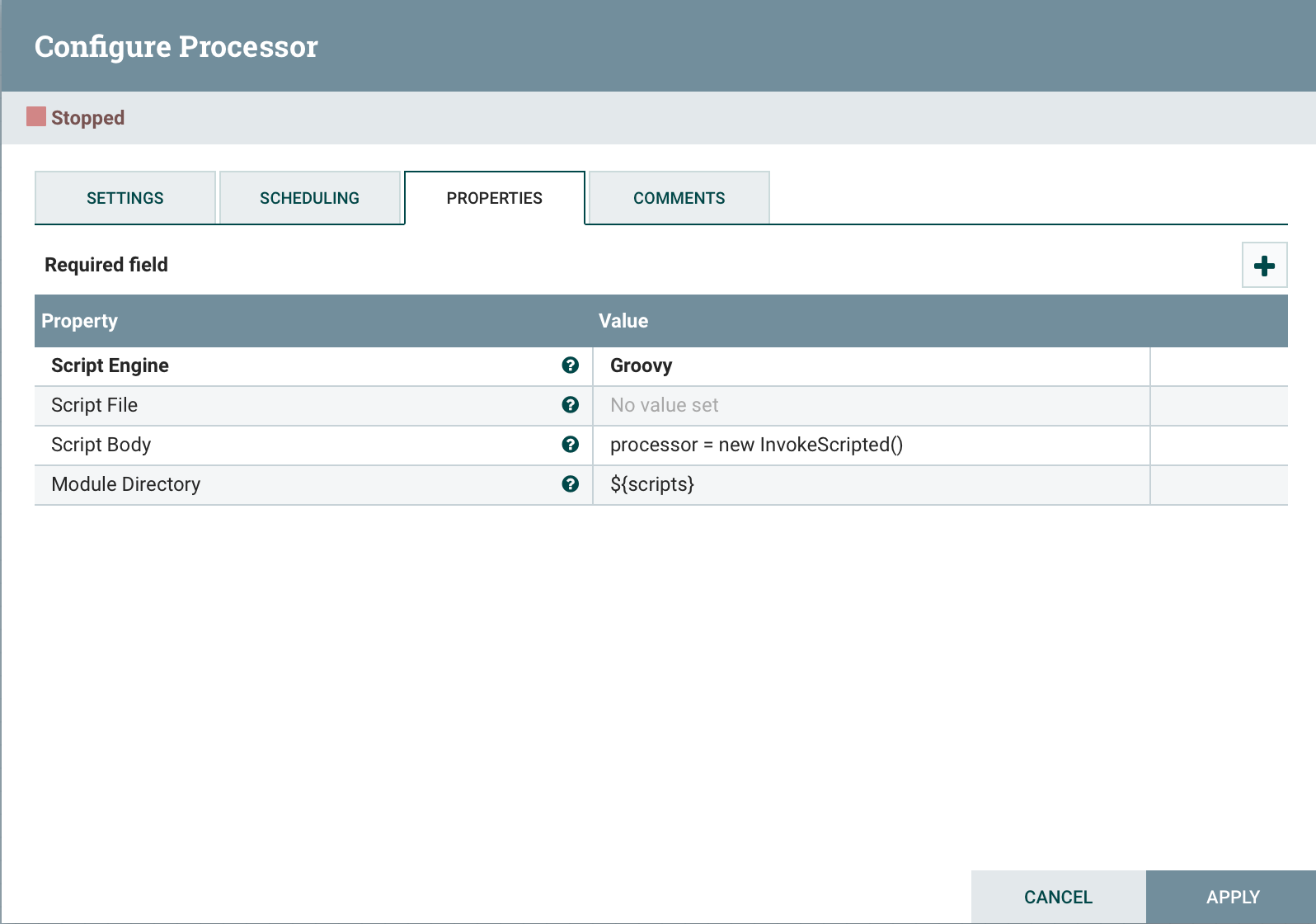
В конец кода добавим processor = new InvokeScripted()
Такой подход похож на создание кастомного процессора.
Заключение
Создание кастомного процессора не самая простая вещь – в первый раз придется поднапрячься, чтобы разобраться, зато польза от этого действия неоспорима.
Пост подготовлен Командой управления данными Ростелекома
You must be registered for see links
Apache Nifi имеет в базовой поставке более 300 процессоров.
NiFi Processor это основной строительный блок для создания dataflow в экосистеме NiFi. Процессоры предоставляют интерфейс, через который NiFi обеспечивает доступ к flowfile, его атрибутам и содержимому. Собственный кастомный процессор позволит сэкономить силы, время и внимание пользователей, так как вместо множества простейших элементов-процессоров будет отображаться в интерфейсе и выполняться всего один (ну или сколько напишете). Так же, как и стандартные процессоры, кастомный процессор позволяет выполнять различные операции и обрабатывать содержимое flowfile. Сегодня мы поговорим о стандартных инструментах для расширения функционала.
ExecuteScript
ExecuteScript – это универсальный процессор, который предназначен для реализации бизнес- логики на языке программирования (Groovy, Jython, Javascript, JRuby). Такой подход позволяет быстро получить нужную функциональность. Для обеспечения доступа к компонентам NiFi в скрипте есть возможность использовать следующие переменные:
Session: переменная типа org.apache.nifi.processor.ProcessSession. Переменная позволяет выполнять операции с flowfile, такими как create(), putAttribute() и Transfer(), а также read() и write().
Context: org.apache.nifi.processor.ProcessContext. Его можно использовать для получения свойств процессора, отношений, служб контроллера и StateManager.
REL_SUCCESS: Отношение «успех».
REL_FAILURE: Отношение «сбой»
Dynamic Properties: Динамические свойства, определенные в ExecuteScript, передаются механизму сценариев в виде переменных, установленные как объект PropertyValue. Это позволяет получить значение свойства, привести значение к соответствующему типу данных, например, логическому и т. д.
Для использования достаточно выбрать Script Engine и указать расположение файла Script File с нашим скриптом или сам скрипт Script Body.
Рассмотрим парочку примеров:
получить один файл потока из очереди
flowFile = session.get()
if(!flowFile) return
Сгенерировать новый FlowFile
flowFile = session.create()
// Additional processing here
Добавить атрибут к FlowFile
flowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
Извлечь и обработать все атрибуты.
flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
Логгер
log.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
В ExecuteScript есть можно использовать расширенные возможности, подробнее об этом можно почитать в статье ExecuteScript Cookbook.
ExecuteGroovyScript
ExecuteGroovyScript имеет такой же функционал, что и ExecuteScript, но вместо зоопарка допустимых языков можно использовать только один – groovy. Главное преимущество этого процессора – это более удобное использование служб сервисов. Помимо стандартного набора переменных Session, Context и т.д. можно определить динамические свойства с префиксом CTL и SQL. Начиная с версии 1.11 появилась поддержка RecordReader и Record Writer. Все свойства представляют собой HashMap, у которого в качестве ключа используется «Имя сервиса», а значение – это конкретный объект в зависимости от свойства:
RecordWriter HashMap
RecordReader HashMap
SQL HashMap
CTL HashMap
Данная информация уже облегчает жизнь, т.к. мы можем заглянуть в исходники или найти документацию по конкретному классу.
Работа с базой данных
Если определить свойство SQL.DB и связать DBCPService, то мы получим доступ к свойству из кода SQL.DB.rows('select * from table')
Процессор автоматически принимает соединение от службы dbcp перед выполнением и обрабатывает транзакцию. Транзакции базы данных автоматически откатываются при возникновении ошибки и фиксируются в случае успеха. В ExecuteGroovyScript можно перехватывать события start и stop, реализовав соответствующие статические методы.
import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS code>
InvokeScriptedProcessor
Еще один интересный процессор. Для его использования нужно объявить класс, который реализовывает интерфейс implements, и определить переменную processor. Можно определить любые PropertyDescriptor или Relationship, также получить доступ к родительскому ComponentLog'у и определить методы void onScheduled(ProcessContext context) и void onStopped(ProcessContext context). Эти методы будут вызваны при наступлении события запуска по расписанию в NiFi (onScheduled) и при остановке (onScheduled).
class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List
getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Логику надо реализовать в методе void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
Описывать все методы, декларированные в интерфейсе излишне, так что обойдемся одним абстрактным классом, в котором объявим следующий метод:
abstract void executeScript(ProcessContext context, ProcessSession session)
Метод мы будем вызывать в
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List
getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
Теперь объявим класс-наследник BaseGroovyProcessorи опишем наш executeScript, также добавим Relationship RELSUCCESS и RELFAILURE.
import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
В конец кода добавим processor = new InvokeScripted()
Такой подход похож на создание кастомного процессора.
Заключение
Создание кастомного процессора не самая простая вещь – в первый раз придется поднапрячься, чтобы разобраться, зато польза от этого действия неоспорима.
Пост подготовлен Командой управления данными Ростелекома